
Text-to-SQL works in demos but breaks in production. The mechanism, the failure modes, and the fix: context engineering for AI agents.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min
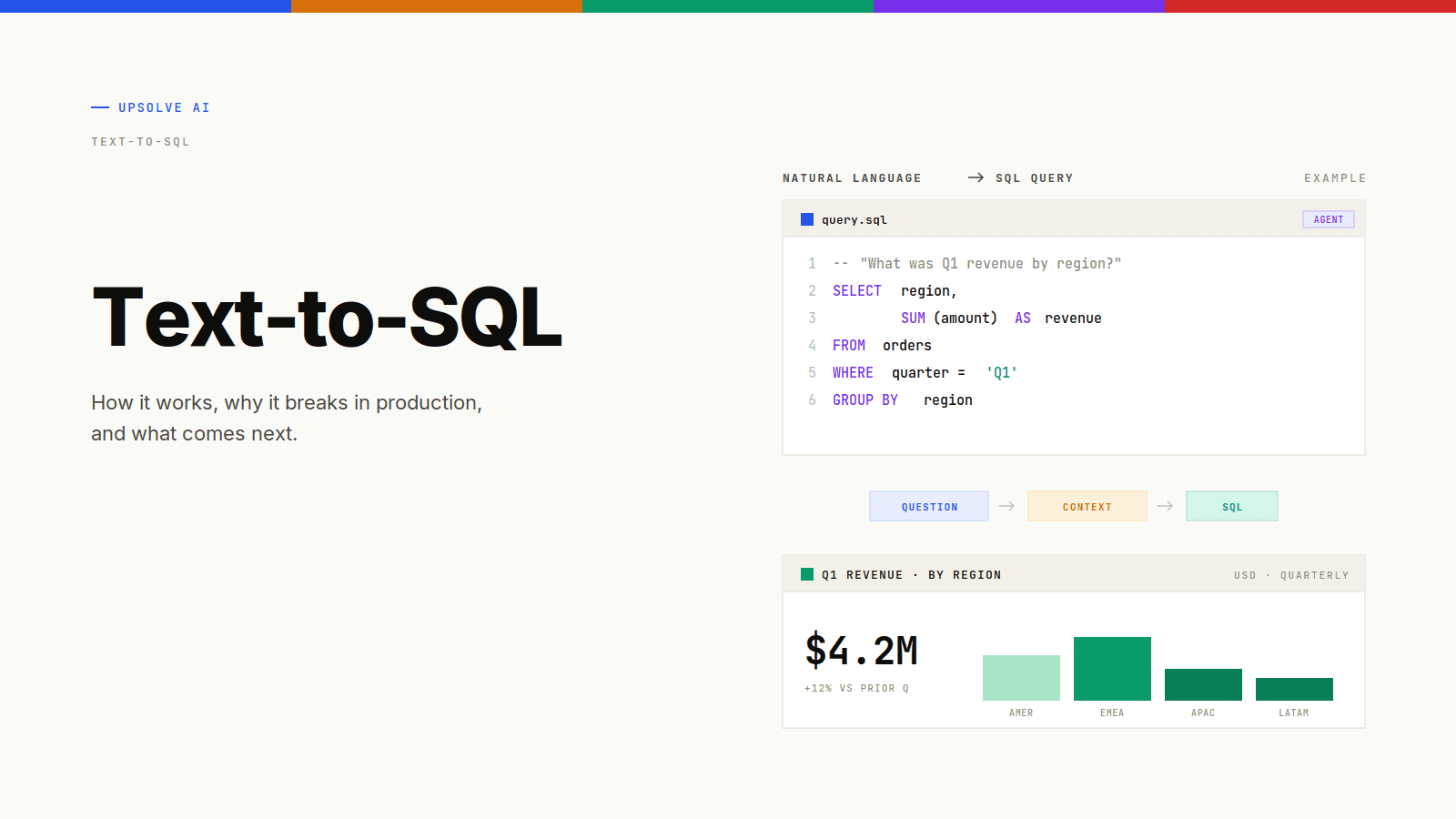
Text-to-SQL is the technique of translating a natural language question (for example, "what was our churn rate last quarter?") into an executable SQL query, running it against a database, and returning the answer. It sits at the heart of every modern analytics agent, every conversational BI tool, and every "chat with your data" feature shipped in the last 18 months. It is also the layer where most of those tools quietly fail.
The strange part is that the failure is no longer about the model. Frontier LLMs can write syntactically valid SQL with high reliability. The failure is about everything around the SQL: which table to pick, what a column means at your company, which definition of "revenue" the analyst would have used, and whether the answer can be trusted enough to act on.
This guide walks through how text-to-SQL works, where it breaks, what the benchmarks actually say, and why the next generation of systems looks less like a translator and more like an agent operating on top of a structured context layer.
Key Takeaways |
|---|
|
What Is Text-to-SQL?
Text-to-SQL (also called NL-to-SQL or natural language to SQL) is a system that takes a question written in plain English and produces a SQL query that answers it. The question can be a one-line ask ("how many users signed up last week?") or a multi-clause request ("for each region, show the top three customers by revenue in Q1, excluding internal accounts"). The system returns either the SQL itself, the result of running the SQL, or both.
The category has existed in some form for over a decade, with early systems built on grammar-based parsers and slot-filling models that worked only on narrow domains. The breakthrough came when large language models trained on code (especially SQL) became good enough to generalize across schemas they had never seen during training. Today, "text-to-SQL" almost always means "text-to-SQL with an LLM at the core."
Vendors describe the same underlying capability with different names. You will see it called text-to-SQL AI, conversational SQL, NL-to-SQL, natural language queries, AI-assisted querying, or simply "ask your data a question." The mechanics are similar; the differences live in what surrounds the SQL generation step, which is where most of the production accuracy comes from.
How Text-to-SQL Works: From Natural Language to Query Result
A modern text-to-SQL system is a pipeline, not a single call. Even the simplest implementations involve several discrete stages, and the more reliable systems wrap those stages in an iterative loop that can retry, self-correct, and re-plan. Here is what happens between the moment a user types a question and the moment they see an answer.
Step 1: Schema Linking and Retrieval
Before the model writes any SQL, it needs to know what tables and columns exist. Schema linking is the process of taking the user's question and identifying which schema elements are relevant. In a small database with a dozen tables, this is trivial. In an enterprise warehouse with thousands of tables, foreign keys spanning a tangled graph, and column names that read like usr_acct_rev_ttl_m, this is where many systems break down.
Modern implementations use retrieval techniques borrowed from RAG (retrieval-augmented generation). The user's question is embedded, compared against embeddings of table descriptions, column names, sample values, and prior queries, and the most relevant subset is passed to the LLM along with the question. Without retrieval, the LLM either gets the entire schema dumped into its context window (expensive and noisy) or works with no schema at all (impossible).
Step 2: SQL Generation by the LLM
With the relevant schema in context, the LLM is prompted to write the SQL. The prompt typically includes the question, the schema subset, sometimes a few examples of similar queries (few-shot prompting), and a system prompt with instructions like "use ANSI SQL" or "always alias subqueries." This is the step that the public imagines when they hear "text-to-SQL."
It is also the step that has improved the most in the last two years. According to the Bird-SQL leaderboard tracked at llm-stats.com, Gemini 2.0 Flash-Lite leads with 57.4%, followed by Gemini 2.0 Flash at 56.9% and Gemma 3 27B at 54.4% on the BIRD dev set when used as a single model without an agentic wrapper. Frontier reasoning models do better. None of them are good enough alone.
Step 3: Query Execution and Result Synthesis
The generated SQL is run against the database. The result set comes back. In a basic system, the rows are formatted into a table or chart and shown to the user. In a more sophisticated system, the LLM is given the result and asked to summarize it in natural language: "Q1 revenue was $4.2M, up 18% over Q4."
This step sounds boring, but it hides several failure points. The SQL might be syntactically valid and execute without error while returning the wrong answer. It might return an empty result when the right answer exists. It might be unsafe (a full table scan on a billion-row warehouse). Production systems wrap execution in safety rails: row limits, timeout enforcement, cost caps, and access controls based on the user's role.
Step 4: Validation, Self-Correction, and the Agent Loop
The simplest text-to-SQL implementations stop at step 3. Modern systems add a fourth step: validation. The agent inspects the SQL or the result, decides whether it looks reasonable, and either returns it, retries with a different query, or asks the user a clarifying question.
This is the difference between a "text-to-SQL converter" and a "text-to-SQL agent." The converter is a one-shot translation; the agent is a loop that can iterate, plan, and recover from errors. We will come back to this distinction, because it is where the next generation of systems is being built. For a deeper look at how natural language analytics goes beyond SQL generation, see our guide to natural language queries for databases.
The State of Text-to-SQL Accuracy: Benchmarks vs. Reality
There are now dozens of text-to-SQL benchmarks, but two matter most for understanding where the field actually stands: BIRD (for query generation accuracy on realistic databases) and DABStep (for multi-step data analysis). Together they tell a story that most vendor marketing pages do not.
BIRD: The Benchmark That Exposed the Spider Gap
BIRD (BIg Bench for LaRge-scale Database Grounded text-to-SQLs) was introduced in 2023 to fix the limitations of Spider, the previous standard. According to the original BIRD paper, the experimental results demonstrate the significance of database values in generating accurate text-to-SQLs for big databases. Even the most popular and effective text-to-SQL models, such as ChatGPT, only achieve 40.08% in execution accuracy, which is still far from the human result of 92.96%.
The benchmark contains 12,751 question-SQL pairs spanning 95 databases (around 33.4 GB total) drawn from real-world sources: financial records, toxicology data, government datasets. Where Spider used small clean databases, BIRD uses dirty data with inconsistent values, requires domain knowledge to interpret columns, and rewards efficient queries through a separate Valid Efficiency Score.
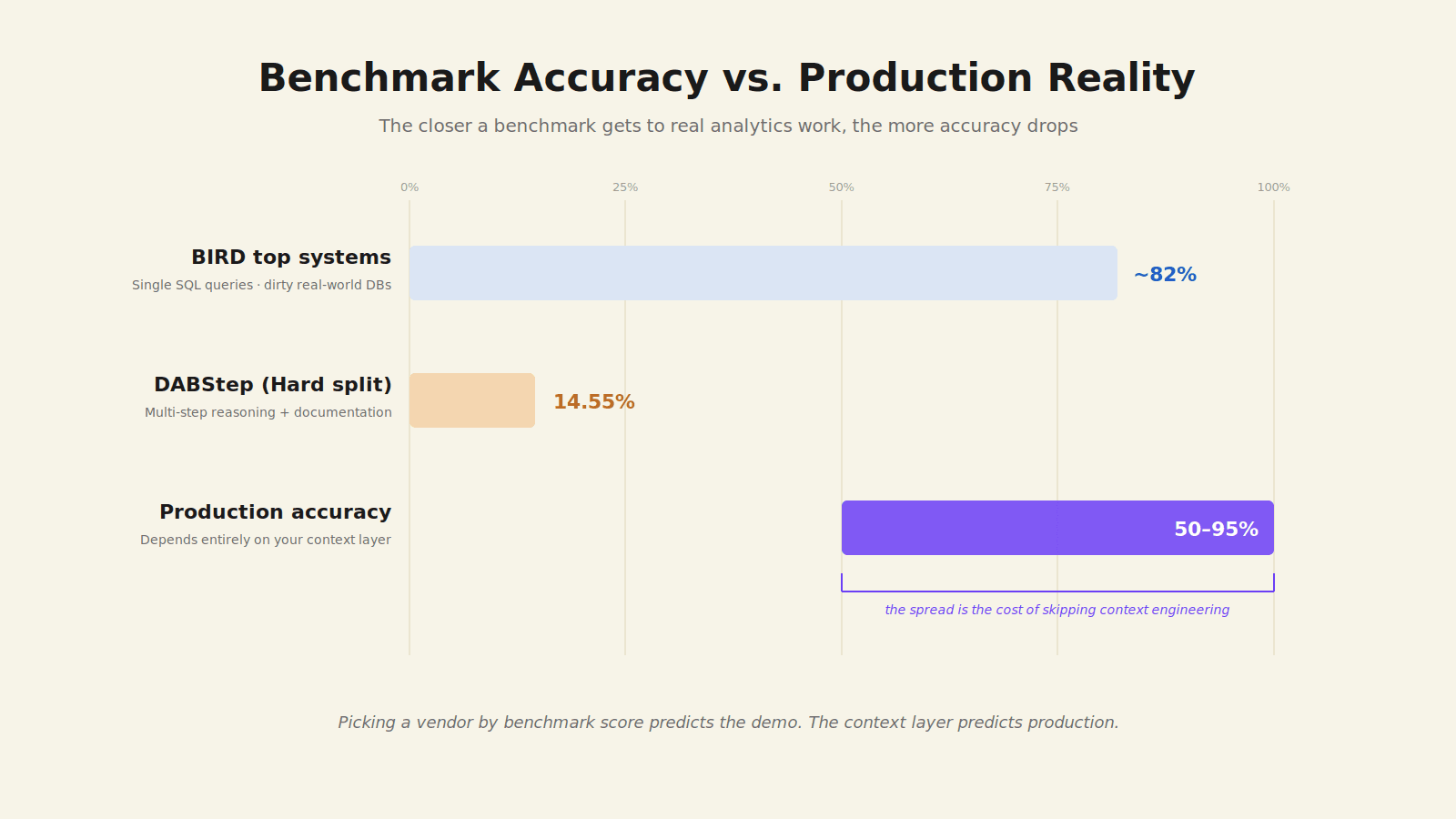
The leaderboard has moved quickly since then. As of 2026, the leading systems on BIRD reach around 81.95% execution accuracy on the test set, with the human baseline still at 92.96%. Most of that improvement came from elaborate multi-step agent pipelines, not from raw model capability.
DABStep: When Multi-Step Reasoning Enters the Picture
BIRD measures the accuracy of a single SQL query against a single question. Real analytics work does not look like that. A typical question requires fetching data, transforming it, joining it with another source, and applying business logic that lives in a PDF or a Slack thread. To measure this, Adyen released DABStep in 2025.
According to the DABStep paper on arXiv, DABstep comprises over 450 real-world challenges derived from a financial analytics platform, requiring models to combine code-based data processing with contextual reasoning over heterogeneous documentation. We evaluate leading LLM-based agents, revealing a substantial performance gap: even the best agent achieves only 14.55% accuracy on the hardest tasks.
Read that again. The hardest split is where production analytics actually lives, and frontier agents are solving roughly one in seven. The gap between BIRD (single-query translation) and DABStep (multi-step analysis with documentation) is the gap between "text-to-SQL works" and "analytics agents work in production."
Benchmark Comparison
Benchmark | What It Measures | Human Baseline | Top System | Key Insight |
|---|---|---|---|---|
Spider | SQL syntax on clean databases | ~92% | >90% | Solved. No longer differentiates systems. |
BIRD | Execution accuracy on dirty real-world databases | 92.96% | ~82% | Gap closing, mostly via multi-step pipelines. |
BIRD-Critic | SQL bug detection and repair | N/A | <50% | Models still struggle to fix their own errors. |
Spider 2-Snow | Snowflake dialect, enterprise complexity | N/A | <50% | Real warehouse dialects lower scores significantly. |
DABStep (Hard) | Multi-step analytics with documentation | N/A | 14.55% | Where text-to-SQL meets real analytics work. |
Why Leaderboard Scores Mislead Buyers
Even when benchmarks improve, the numbers can mislead. A widely cited 2026 analysis from the VLDB paper "Text-to-SQL Benchmarks are Broken" found that in a random sample of 100 out of 1534 problems from BIRD Dev, we identified significant performance changes ranging from −2% to 19% in absolute terms and ranking position changes ranging from −2 to 3. For instance, we find the performance of CHESS, an agent previously ranked 4th among our five selected agents, increases from 62% to 81% after corrections and moves to 1st place.
In other words, the gold standard answers in the benchmark contain mistakes, and the leaderboard rankings shift dramatically once you fix them. As MotherDuck pointed out in February 2026, strict benchmark accuracy of 58-64% can correspond to 94-95% practical accuracy in production when the system has access to a semantic layer and a human or LLM review step. The benchmark number is a noisy lower bound, not a forecast of what users will experience.
Vendor reports trend in the same direction. According to an evaluation summary on Querio, top-performing models on the Spider leaderboard may achieve over 90% accuracy based on Exact Match, while their real-world Execution Accuracy can drop to just 51%. The translation from "the model can write SQL" to "the user gets the right answer" is where production failure modes pile up.
Why Text-to-SQL Breaks in Production
When teams move a text-to-SQL system from a sandbox demo to a real warehouse with real business users, the failure modes are remarkably consistent. They are not random; they cluster into four categories. Understanding which category is failing matters more than picking a better LLM.
The Schema Problem: Tables Don't Explain Themselves
Enterprise schemas are messy. Tables get added, deprecated but never dropped, renamed for compliance, and joined through keys that only one person on the data team understands. A column named status_code could mean three different things depending on which subsystem wrote the row. None of this is encoded in the schema itself.
Text-to-SQL models, even with retrieval, have no way to know that the orders_v2 table is the current source of truth and orders_legacy is a deprecated mirror that gets updated weekly through a broken DAG. They pick whichever looks more relevant to the question and produce a query that is technically correct against the wrong table.
The fix here is not a better model. It is a schema layer that encodes which tables are authoritative, which are deprecated, how they relate, and what the columns actually mean. This is what a16z calls the "Structure" layer in their March 2026 piece on data agent context: the foundation on which everything else sits.
The Meaning Problem: What Counts as "Revenue"?
Ask a finance team and a sales team what "revenue" is and you will get two different answers. ARR? Booked revenue? Recognized revenue? Net of refunds? Gross or net of platform fees? Each definition produces a different SQL query and a different number.
This is the Meaning problem, and it is the single largest failure point in production text-to-SQL. A model that does not know your company's specific definitions will pick a plausible interpretation, generate correct-looking SQL, and confidently return a number that is wrong by 12%. The user has no way to detect the error unless they already know the right answer.
Semantic layers (from tools like dbt's MetricFlow, Cube, or LookML) were built to solve exactly this. They encode metric definitions, dimensions, and business rules in one place, so that "revenue" always means the same thing no matter who asks. When a text-to-SQL system has access to the semantic layer, the Meaning problem gets smaller. We cover this in depth in our guide to the semantic layer's role in query accuracy.
The Trust Problem: One Wrong Answer Breaks Adoption
Imagine a CFO asks the agent for last quarter's revenue, gets a number, presents it in the board meeting, and discovers later that the agent excluded a product line. They will never use the agent again. Worse, neither will their team.
Text-to-SQL accuracy is not measured at the average; it is measured at the worst case. A system that is right 95% of the time but spectacularly wrong on the 5% that matters is a system that no one will trust. This is why Claire Gouze observed in her independent review of 14 analytics agents, text to SQL tools seem still WIP. End user UX is new, data teams often need to rebuild context in them, and have no guarantee of reliability.
The fix is a Trust layer: a record of which questions have been answered correctly before, which queries have been validated by analysts, and which results have been flagged. When the agent encounters a question similar to one it has already answered well, it should reuse the verified path rather than generating from scratch. This is the layer that almost no text-to-SQL benchmark measures and almost no off-the-shelf tool ships with.
The Ambiguity Problem: 20% of Real Questions Are Unclear
Users do not write questions like benchmark prompts. They write "show me top customers" and expect the system to figure out that "top" means revenue this quarter, "customer" means active accounts, and "show me" means a sortable table. According to the Querio benchmark evaluation, research shows that 20% of user questions are problematic, including ambiguous or unanswerable queries.
A text-to-SQL system that silently guesses on ambiguous questions is more dangerous than one that asks. The harder design problem is teaching the agent to recognize ambiguity in the first place. This requires knowing both what the user probably meant and what alternatives exist. Both are context problems, not modeling problems.
Text-to-SQL Agents vs. Simple Converters
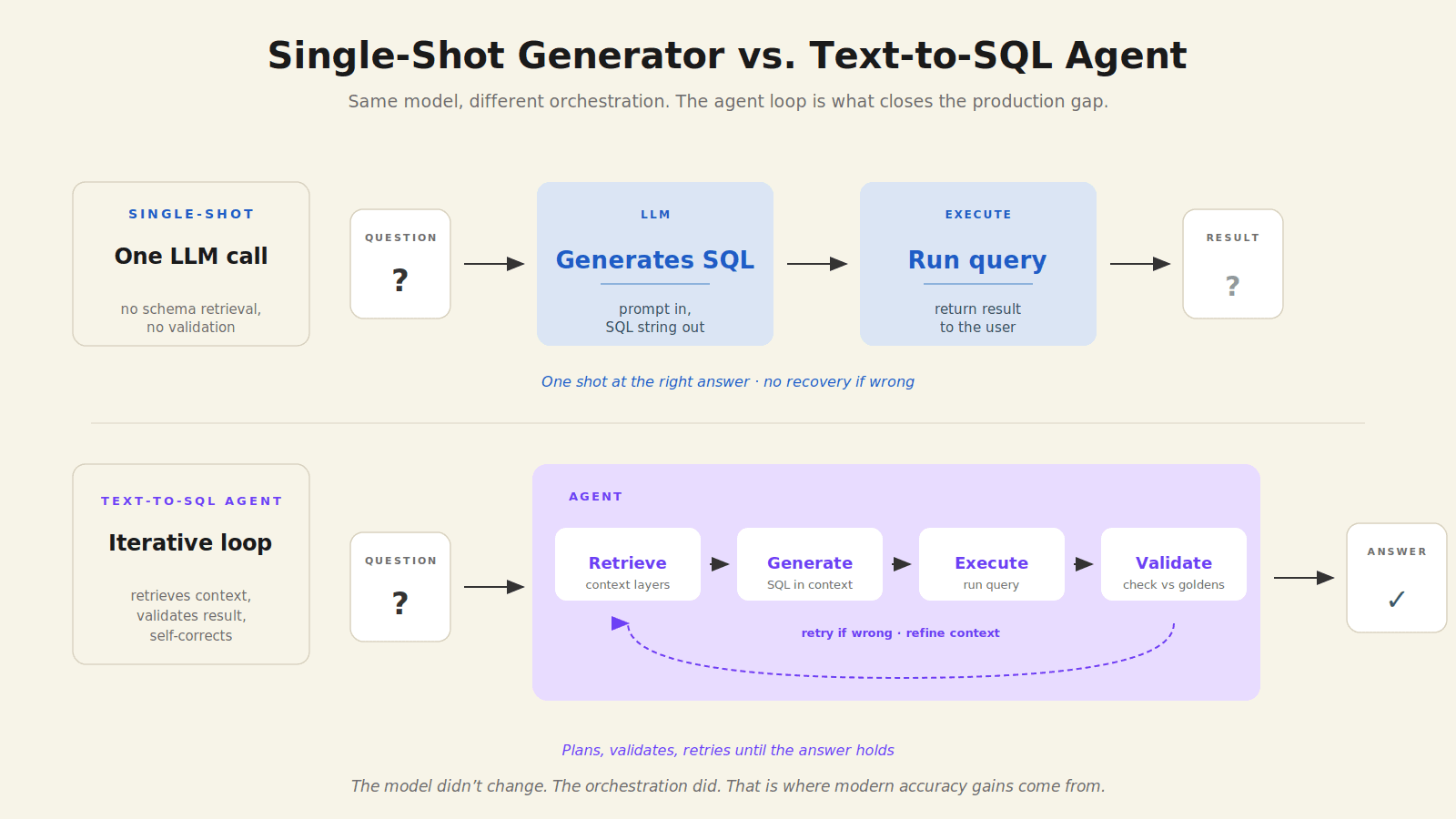
The text-to-SQL category split into two distinct classes around 2024. They are sold under the same name but behave very differently.
Single-Shot Generators
The simpler approach is one LLM call: prompt in, SQL out. These systems are cheap, fast, and often impressive in a demo. They power most "AI in the SQL editor" features inside warehouse tools and BI platforms. Their accuracy is bounded by what the model can do with the schema you give it, and they have no mechanism to recover when the first attempt is wrong.
Single-shot generators work well for two use cases: (1) developers writing exploratory queries who can verify the SQL themselves, and (2) very narrow domains with small, well-documented schemas. They do not work well as the engine behind a customer-facing analytics agent.
Agentic Systems with Validation Loops
The more reliable approach treats text-to-SQL as one tool in a larger agent loop. The agent plans, retrieves schema and context, generates a draft query, executes it, validates the result (often using a second LLM call as a judge or comparing against historical patterns), and either returns the answer or retries with a refined approach. Some systems also include a clarification step where the agent asks the user a follow-up question rather than guessing.
This is what gives top systems on BIRD their accuracy gains. The base model has not changed; the orchestration around it has. The leaderboard has moved up by roughly twenty percentage points over the last two years not because LLMs got dramatically better at SQL, but because the systems wrapping them got better at retrieval, validation, and recovery.
The downside is cost and latency. An agentic system might make 5-15 LLM calls per question, each with retrieval steps, and each adding latency and dollar cost. The economics only make sense when the accuracy gain matters more than the unit cost.
What Modern Systems Add (and Where They Still Fall Short)
The strongest text-to-SQL agents shipping in 2026 add some combination of: schema retrieval with embedded table descriptions, few-shot example libraries (pulling similar past questions into the prompt), semantic layer integration (dbt MetricFlow, Cube), validation against golden query sets, LLM-as-judge evaluation of results, and feedback loops that improve over time.
What they still struggle with is everything that is not encoded anywhere: the tribal knowledge that lives in analysts' heads, the unwritten rules about which numbers go in which report, the seasonal exceptions, and the just-fixed bugs in a join. Until that knowledge is captured in a structured context layer, even the best agents will plateau.
What Comes Next: From Text-to-SQL to Context Engineering
The shift in the field over the past 18 months can be summarized in one line: the failure was not the model; the failure was context. This is the lesson from the BIRD plateau, from DABStep's 14% scores on hard tasks, and from every analytics agent that demoed well and stalled in production.
The next generation of systems is being built around an explicit context layer. OpenAI's January 2026 writeup of their in-house data agent describes six context layers their team built; the framing that has stuck in the industry collapses these into three: Structure (what data exists and how it connects), Meaning (what the data means at this specific company), and Trust (which answers have been verified). Text-to-SQL becomes one tool the agent uses, not the agent itself.
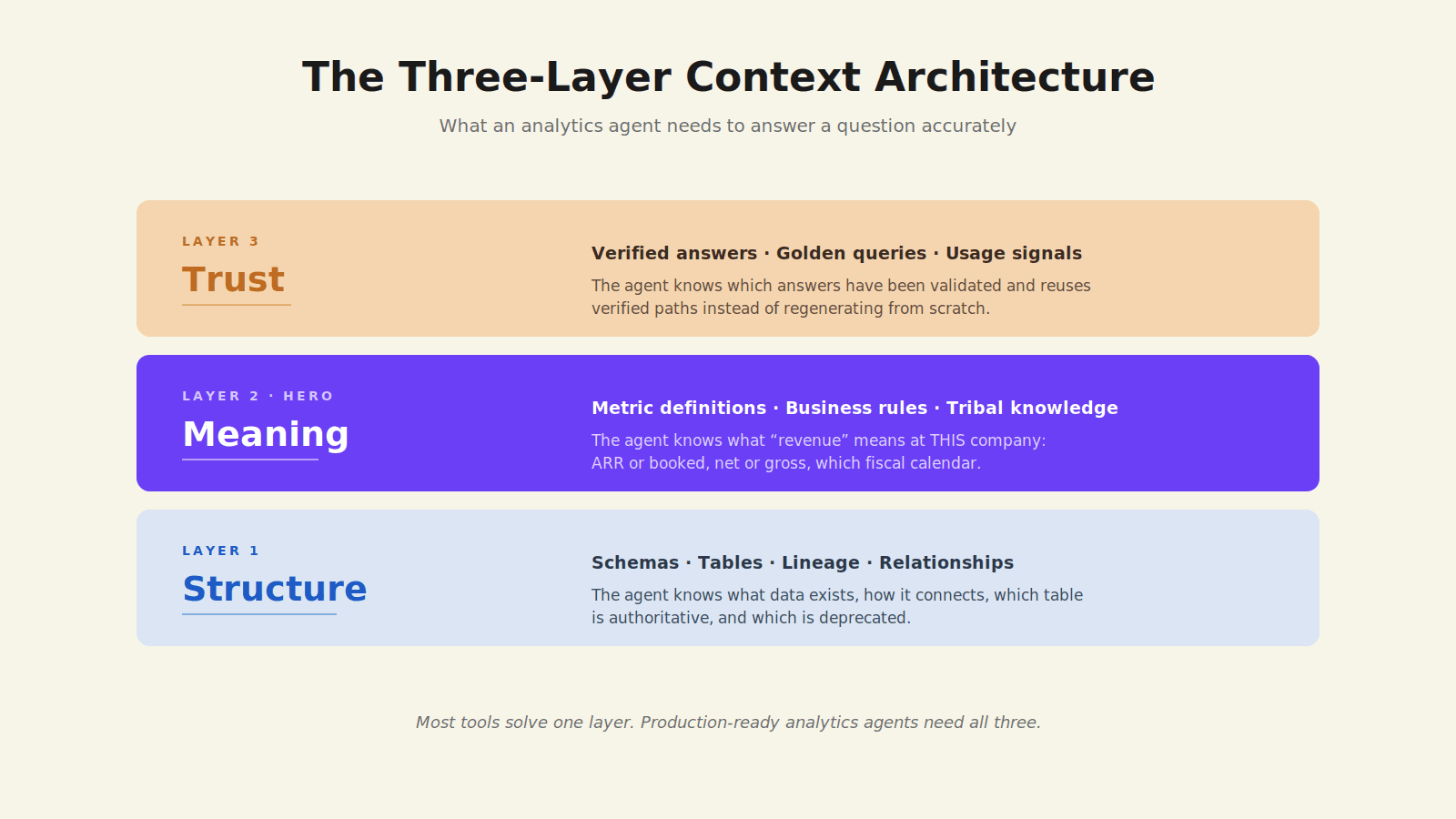
The implication for buyers is that the question to ask vendors is no longer "how accurate is your text-to-SQL?" It is "how do you encode context, and how does that context improve over time?" A platform with a 95% benchmark score and no context infrastructure will fail in production faster than a platform with an 80% benchmark score and a structured way to encode institutional knowledge.
This is the broader category shift we explore in our guide to context engineering for analytics, the most important piece of the puzzle for any team building or buying analytics agents. If you are reading this because you tried building a text-to-SQL feature and hit the accuracy wall, that is where to go next.
How to Evaluate Text-to-SQL Accuracy for Your Stack
Before picking a platform or building one, build a small evaluation harness. This does not need to be elaborate. The minimum useful version is a list of 50 real questions from your business users, the SQL an analyst would write to answer them, and the verified result.
Run candidate systems against this set and measure four things: execution accuracy (did the right rows come back), semantic accuracy (was the business meaning correct, judged by an analyst or an LLM-as-judge), failure modes (when it was wrong, why), and consistency (does asking the same question twice produce the same answer). A 50-question set is enough to differentiate serious candidates from demoware.
The deeper version of this evaluation, including how to build golden query sets, monitor production drift, and catch context regressions, is covered in our analytics agent evaluation framework. If you are at the platform evaluation stage, the criteria that separate production-ready systems from impressive demos are the same criteria covered in the next section.
See How Modern Analytics Agents Solve the Context Problem
If you have read this far, you already know that text-to-SQL alone is not enough. The platforms that ship production-ready analytics agents in 2026 are the ones built around structured context, not just a strong SQL generator. To see how different platforms handle context, evaluation, and reliability, read our guide to AI agent builder platforms for analytics.
Frequently Asked Questions
What is text-to-SQL?
Text-to-SQL is a system that takes a natural language question (like "what was revenue last quarter?"), translates it into a SQL query, runs the query against a database, and returns the answer. Modern text-to-SQL is powered by large language models and is the underlying technology behind most "chat with your data" features.
How accurate is text-to-SQL in 2026?
On the BIRD benchmark, top systems reach around 82% execution accuracy compared to a human baseline of 92.96%. On harder multi-step analytics benchmarks like DABStep, the best agents reach only 14.55% on the hard split. Real production accuracy varies widely and depends far more on the surrounding context layer than on the model.
What is the difference between text-to-SQL and a natural language query?
A natural language query (NL query) is the user-facing concept: asking a database a question in plain language. Text-to-SQL is the underlying technique that makes most NL query systems work today, by generating SQL from the question. A natural language query system can also be powered by other techniques (such as direct table search or pre-built metric definitions) that do not generate SQL.
Is text-to-SQL the same as an analytics agent?
No. Text-to-SQL is a component; an analytics agent is a system that uses text-to-SQL alongside schema retrieval, planning, validation, and self-correction to answer business questions reliably. A simple text-to-SQL tool returns a query; an analytics agent returns a verified answer. We cover the distinction in detail in our analytics agent guide.
Why do text-to-SQL tools fail in production?
The most common failures are not SQL syntax errors. They are context failures: the system picks the wrong table, uses the wrong definition of a business metric like "revenue," or silently guesses on ambiguous questions. The fix is structural, not a better model. Schema, business meaning, and trust signals need to be encoded somewhere the agent can access them.
Do I need a semantic layer to use text-to-SQL?
A semantic layer (such as dbt MetricFlow, Cube, or LookML) significantly improves text-to-SQL accuracy because it encodes business metric definitions consistently. It is not strictly required, and some platforms can encode context without one. But for any team where the definition of common metrics (revenue, active users, retention) matters, a semantic layer or equivalent context infrastructure is the difference between answers that hold up in a board meeting and answers that quietly drift.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







