
Your analytics agent does not need a better model. It needs better context. See how context engineering improves accuracy in production.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min

Context engineering for AI is the discipline of curating, structuring, and delivering the institutional knowledge an analytics agent needs to produce trustworthy answers. It encompasses schema mappings, metric definitions, business rules, tribal knowledge, access controls, and validated query patterns, all organized so an agent can reason accurately over your company's data. Without it, even the most advanced language models produce answers that are technically correct SQL but semantically wrong for your business.
If your team has built an analytics agent that performed brilliantly in a demo and then fell apart with real users, the problem almost certainly was not the model. The problem was context.
Key Takeaways |
|---|
|
Why Context Engineering Matters for Analytics Agents
The analytics industry spent the last two years learning an expensive lesson. Organizations connected language models to their data warehouses, built slick chat interfaces, and demonstrated impressive demos to leadership. Then real users asked real questions, and the agents failed.
In fact, IDC research conducted with Lenovo found that 88% of AI proofs of concept never graduate to production deployment. The authors attributed the low conversion rate to insufficient organizational readiness in terms of data, processes, and IT infrastructure. For analytics agents specifically, the failure point is even more predictable: the agent does not understand what your data means.
This is where context engineering enters the picture. Think of it like this: hiring a brilliant analyst who has never worked at your company. They know SQL. They understand statistics. But they do not know that "revenue" at your organization means ARR excluding professional services, that Q1 starts in February because of your fiscal calendar, or that the fct_revenue table was deprecated six months ago in favor of mv_revenue_monthly. Without that institutional knowledge, even the most capable analyst produces wrong answers confidently.
Key Insight: The failure was not the model. The failure was context. Every organization that has successfully deployed an analytics agent at scale has invested heavily in structuring the institutional knowledge that makes answers trustworthy.
The Gap Between Technical Accuracy and Semantic Accuracy
This is one of the most misunderstood distinctions in the analytics agent space. There are two dimensions to whether an answer is "correct":
Technical accuracy: Did the agent write valid SQL that executes against the right tables and returns data? Most modern language models achieve reasonable technical accuracy on well-structured schemas.
Semantic accuracy: Does the answer mean what the business user thinks it means? Is "revenue" calculated the way your CFO defines it? Does "last quarter" align with your fiscal calendar? Are inactive customers excluded from the count?
Text-to-SQL benchmarks like Spider 2.0 and BIRD measure technical accuracy. But in production, semantic accuracy is what determines whether business users trust the agent or abandon it after a week. Context engineering is the discipline that bridges this gap.
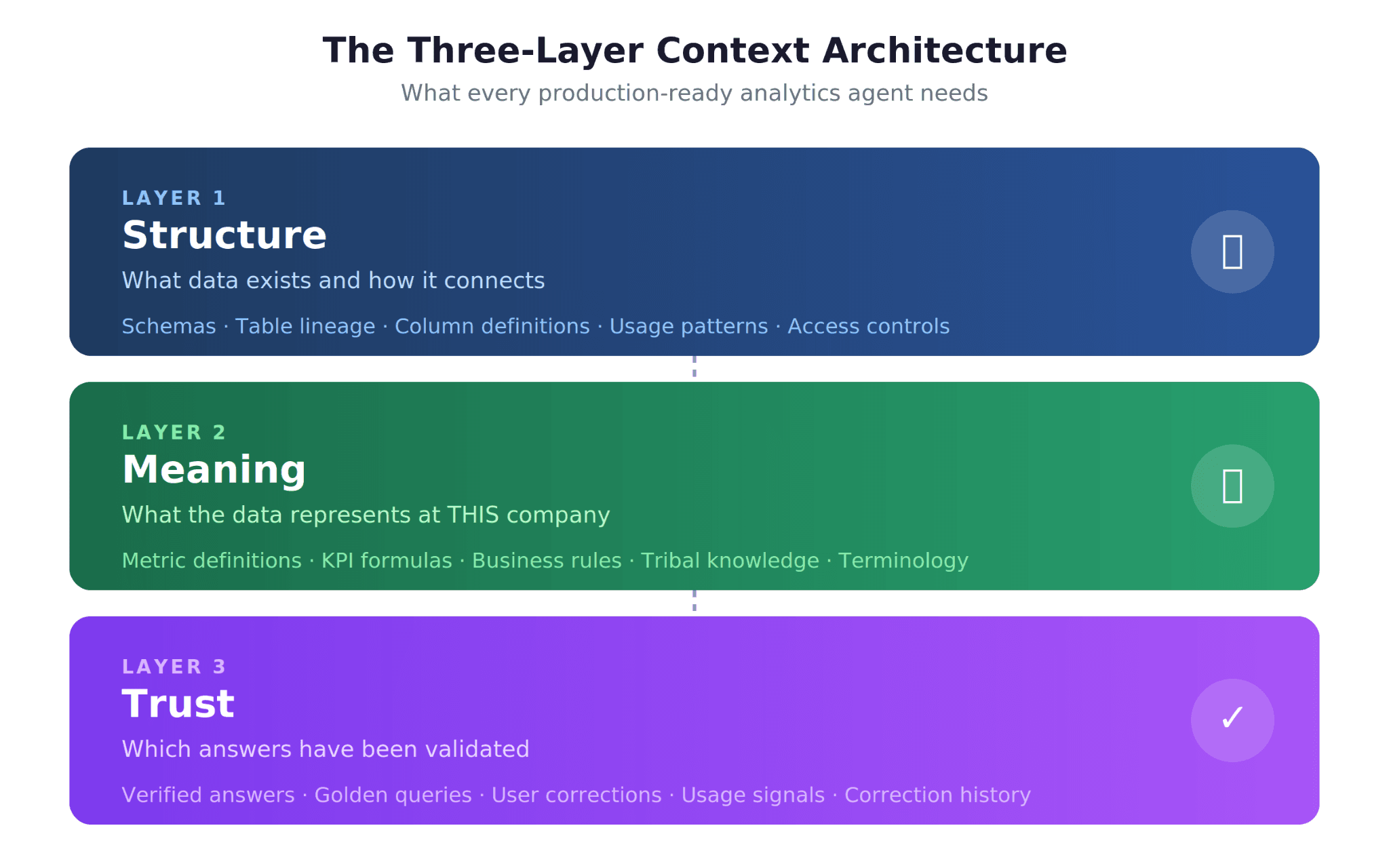
The Three-Layer Context Architecture
After studying how successful analytics agents work in production, including OpenAI's internal data agent and the patterns described in a16z's analysis, a clear architectural pattern emerges. Every reliable analytics agent needs three distinct layers of context, and most failed deployments can trace their problems to a missing or incomplete layer.
Layer 1: Structure (What Data Exists)
The Structure layer answers the foundational question: what data does the agent have access to, and how does it connect?
This layer includes:
Schema metadata: Table names, column definitions, data types, and primary/foreign key relationships
Data lineage: Where each table originates, how it was transformed, and how fresh it is
Usage patterns: Which tables are actively queried, which are deprecated, and which are authoritative sources of truth
Access controls: Which users can see which data, row-level security policies, and PII flags
Without the Structure layer, an agent cannot even begin to answer questions. It is the equivalent of handing someone a filing cabinet with no labels. OpenAI's data agent, which serves over 3,500 internal users, addresses this by combining table-level metadata with usage signals to help the agent identify the correct data source among 70,000 datasets.
Pro Tip: The most common Structure layer failure is stale metadata. If your schema documentation was last updated when a data engineer left the company, the agent is working with an outdated map. Automated schema crawlers that sync metadata on a schedule are not optional; they are foundational.
Layer 2: Meaning (What the Data Means at THIS Company)
The Meaning layer is where most analytics agents fail, and it is the layer that separates a generic AI chatbot from a production-ready analytics agent. It answers: what do the numbers actually mean in the context of your specific business?
This layer includes:
Metric definitions: How your organization calculates revenue, churn, engagement, conversion rate, and every other KPI
Business rules: Fiscal calendar definitions, customer segmentation logic, regional reporting differences, exclusion criteria
Tribal knowledge: The undocumented conventions that experienced analysts carry in their heads, such as "always exclude the test account," "the UK data is delayed by 48 hours," or "the marketing team uses a different attribution model than finance"
Terminology mappings: When a VP of Sales says "pipeline," do they mean the same thing as when the CFO says it?
This is the layer that a16z's analysis highlights as the critical gap. As the authors describe, traditional semantic layers in the context of BI tools are useful for specific metric definitions, but a modern data context layer needs to be a superset of what a semantic layer traditionally covers: canonical entities, identity resolution, instructions to decode tribal knowledge, and governance guidance.
The Meaning layer is also where the traditional semantic layer fits in. If your organization maintains a well-curated semantic layer through tools like dbt MetricFlow or Cube, that becomes a strong foundation for the Meaning layer. But a semantic layer alone is not sufficient. It defines metrics but rarely captures the tribal knowledge, edge cases, and business rule exceptions that trip up agents in production.
Layer 3: Trust (Which Answers Are Validated)
The Trust layer is the least understood and most frequently skipped. It answers: how does the agent know which of its answers are reliable, and how does it improve over time?
This layer includes:
Verified answers (golden queries): A library of question-answer pairs that have been validated by human analysts and serve as ground truth
Golden assets: Dashboards, reports, and query patterns that are considered authoritative sources
Usage signals: Which answers users accepted, which they corrected, and which they flagged as wrong
Correction history: A memory system that stores non-obvious corrections so the agent does not repeat mistakes
OpenAI's data agent implements a version of this through what they describe as a continuously learning memory system. The agent stores corrections and constraints from user interactions, and this accumulated knowledge improves its accuracy over time. This is not a nice-to-have feature; it is the mechanism that makes an agent production-ready rather than demo-ready.
Key Insight: Most competitors and in-house builds solve one or two layers but not all three. A well-maintained semantic layer addresses the Meaning layer. A good data catalog covers the Structure layer. But almost no one builds the Trust layer, and that is where production deployments break down.
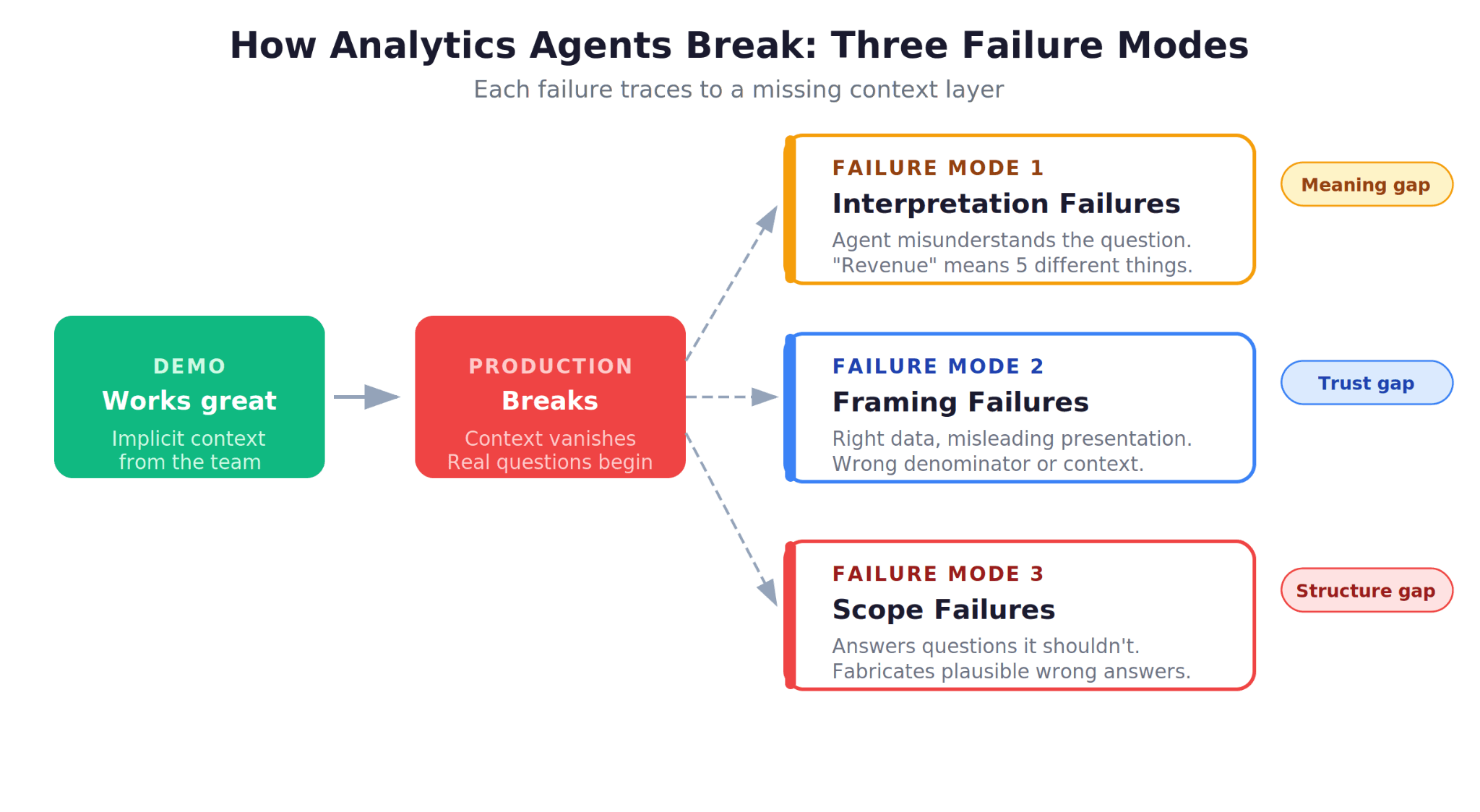
Why Most Analytics Agents Fail: The Context Diagnosis
If your analytics agent works in demos but fails in production, the diagnosis almost always maps to one of these context failures.
1. Structure Gaps
The agent queries the wrong table because it does not know which source is authoritative. Your warehouse has fct_revenue, mv_revenue_monthly, stg_revenue_raw, and tmp_revenue_backup. The agent picks one at random, or picks the one with the name that seems most relevant, which may not be the correct source.
The fix: Encode table authority rankings, deprecation flags, and recommended sources into the Structure layer. An experienced analyst at your company knows instinctively which table to use. The agent needs that same knowledge made explicit.
2. Meaning Gaps
The agent writes technically correct SQL but returns a number that does not match what the business user expects. "Revenue" is calculated differently by the sales team, the finance team, and the product team. The agent used one definition; the user expected another.
This is the challenge a16z describes in detail: a simple question like "What was revenue growth last quarter?" requires knowing whether the user means ARR or run rate, which fiscal quarter boundary applies, and whether new product lines are included.
The fix: Maintain explicit metric definitions with version history, and build disambiguation logic that asks clarifying questions when a query maps to multiple definitions.
3. Trust Gaps
The agent returns an answer, the user accepts it, but the answer is subtly wrong in ways that are difficult to detect. There is no mechanism to flag that the answer contradicts a previously validated report, no way for analysts to mark answers as verified, and no feedback loop to prevent the same mistake from recurring.
The fix: Build a golden query library, implement human-in-the-loop validation workflows, and create a correction memory that persists across sessions.
What OpenAI Learned Building Their Internal Data Agent
OpenAI's engineering blog post on their in-house data agent is one of the most instructive case studies in production-grade context engineering. The agent serves over 3,500 employees, reasons across 600 petabytes of data spanning 70,000 datasets, and was built by just two engineers in three months.
The key lessons for analytics engineering teams:
Context Is Multi-Layered by Design
OpenAI's agent uses multiple layers of context, including table usage metadata, human annotations providing semantic meaning, code-level data definitions, institutional knowledge from internal documents, and a memory system that stores learned corrections. This mirrors the three-layer architecture: Structure (table metadata and usage), Meaning (annotations and institutional knowledge), and Trust (memory and corrections).
The Agent Must Live Where Users Work
The OpenAI agent is deployed across Slack, a web interface, IDEs, the Codex CLI, and their internal ChatGPT app. This is not a cosmetic choice. Distribution across multiple surfaces is what drives adoption, and adoption is what generates the feedback data that fuels the Trust layer.
Self-Improvement Is Not Optional
The agent's continuously learning memory system means every interaction is an opportunity to improve. When a user corrects an answer, that correction becomes part of the agent's context for future queries. This compound improvement loop is what separates a production agent from a demo.
Pro Tip: If your analytics agent does not have a mechanism for learning from user corrections, it will plateau in accuracy. The first month of deployment generates the most valuable training signal. Build the feedback infrastructure before launch, not after.
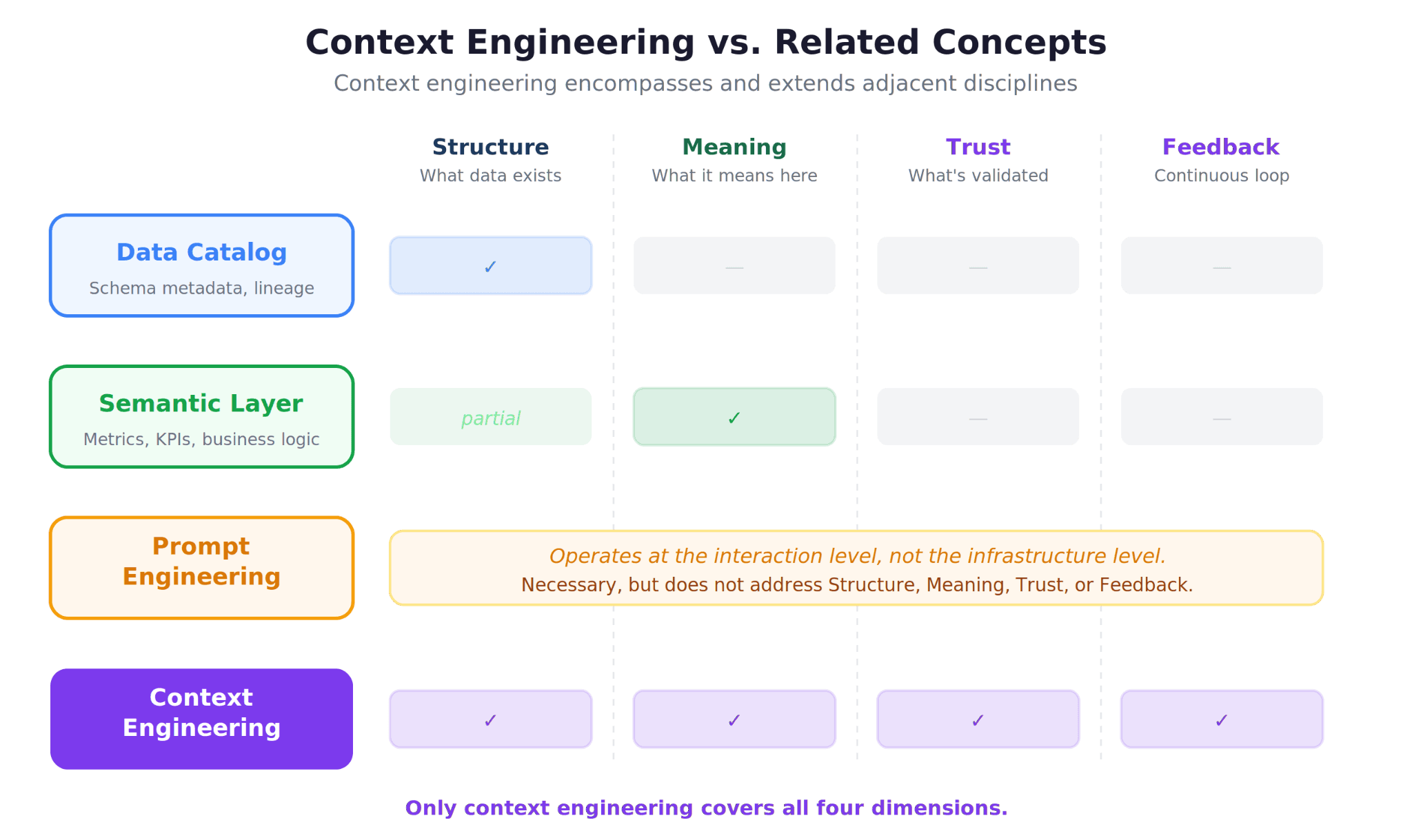
How Context Engineering Differs from Related Concepts
If you have been working in the data space, context engineering may sound like it overlaps with concepts you already know. Here is how it relates to, and differs from, adjacent disciplines.
Context Engineering vs. Semantic Layers
A semantic layer is a specific implementation of the Meaning layer. It defines metrics, dimensions, and business logic in a structured format that BI tools can consume. Context engineering encompasses the semantic layer but extends far beyond it. It includes schema metadata (Structure), tribal knowledge that does not fit neatly into YAML definitions (Meaning), and validated answers and correction history (Trust).
In fact, many organizations do not have a well-maintained semantic layer at all. Context engineering provides a framework for building the equivalent from scratch, without requiring a pre-existing semantic model.
Context Engineering vs. Prompt Engineering
Prompt engineering focuses on crafting better instructions for a single model interaction. Context engineering focuses on designing what the model knows before it receives any prompt. As Cognizant CIO Neal Ramasamy articulated, prompt engineering optimizes an interaction between a user and the system, while context engineering defines the operating system that interaction runs on.
For analytics agents, prompt engineering is necessary but insufficient. You can craft the perfect prompt, but if the agent does not know how your company defines "active customer," no amount of prompt optimization will produce the right answer.
Context Engineering vs. Data Catalogs
Data catalogs (tools like Alation, Atlan, or DataHub) provide metadata management, which maps primarily to the Structure layer. They are excellent at answering "what data exists?" but typically do not capture business rule exceptions, tribal knowledge, or validated query patterns. A data catalog is a component of context infrastructure, not a replacement for it.
Building a Context Engineering Practice: A Framework
If you are an analytics engineering lead looking to improve your agent's accuracy, here is a practical framework for building context engineering into your workflow.
Step 1: Audit Your Existing Context
Start by mapping what context your organization already has and where the gaps are.
Context Type | Where It Might Live Today | Layer |
Schema metadata | Data catalog, dbt docs, warehouse metadata | Structure |
Table authority rankings | Analyst team knowledge, undocumented | Structure |
Metric definitions | Semantic layer, BI tool configs, spreadsheets | Meaning |
Business rules | Confluence pages, Slack threads, tribal knowledge | Meaning |
Validated queries | Saved BI reports, analyst notebooks | Trust |
Correction history | Nowhere (most common gap) | Trust |
Step 2: Encode Context Systematically
Move context out of people's heads and Slack threads into structured, machine-readable formats. This does not require building everything from scratch. Many organizations already have fragments of context scattered across tools. The work is consolidation and structuring.
For the Structure layer, automated schema crawlers and dbt documentation can handle most of the work. For the Meaning layer, the investment is heavier: you need to interview subject matter experts, document metric definitions, and capture the business rules that experienced analysts know intuitively. For the Trust layer, you need to build a golden query library and implement feedback workflows.
Step 3: Evaluate Continuously
Context engineering is not a one-time project. It is a continuous practice. Build an evaluation framework that tests your agent against a set of validated question-answer pairs. When accuracy drops, diagnose which layer of context is responsible and address the gap.
Claire Gouze's analytics agent benchmark demonstrated this principle in practice: after testing 14 analytics agents on real data, the differentiator between tools was not model quality but how effectively each tool leveraged structured context to produce accurate results.
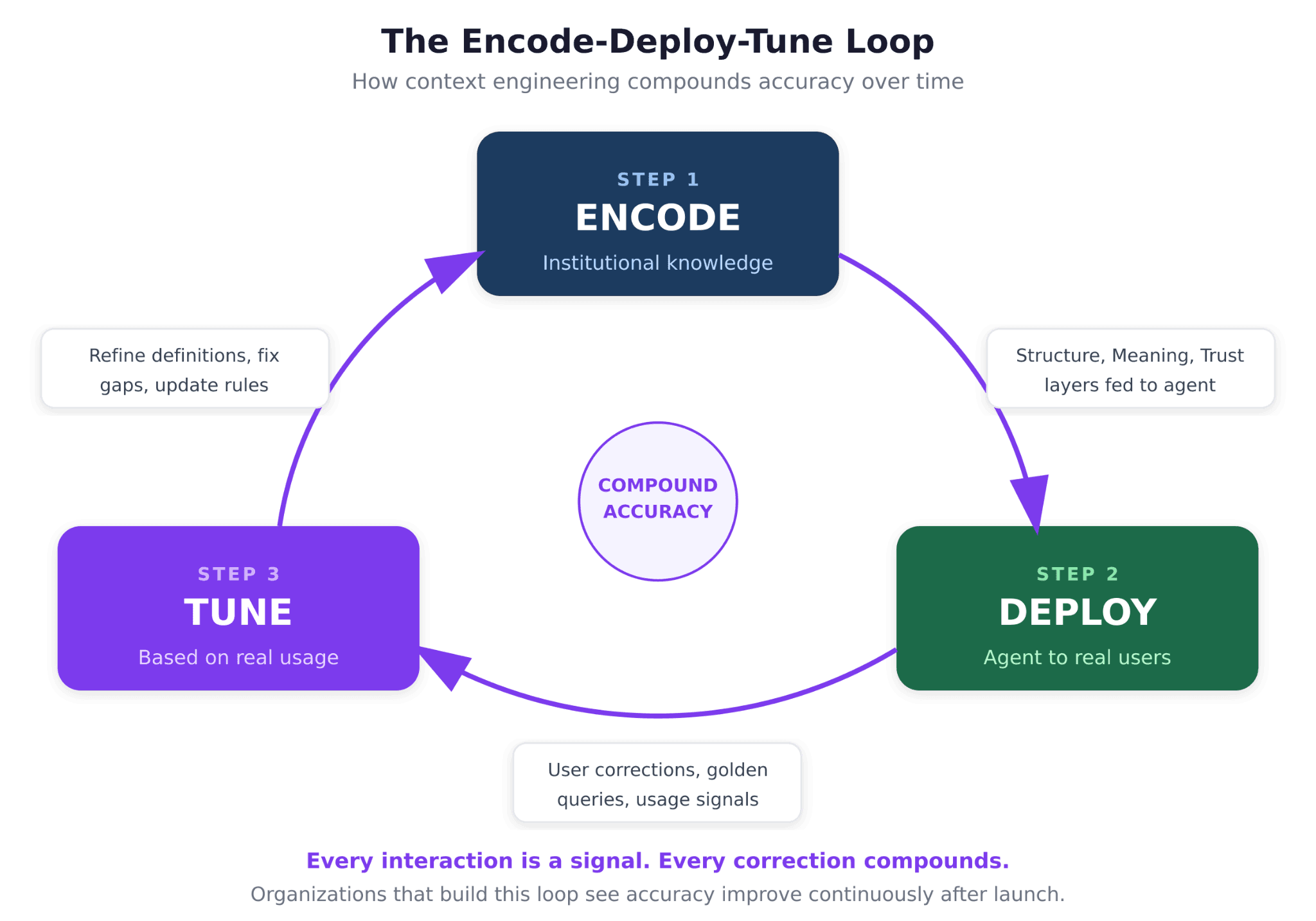
Step 4: Close the Feedback Loop
Every user interaction with your agent is a signal. When a user accepts an answer, that is a weak positive signal. When they correct an answer, that is a strong training signal. When they abandon a conversation, that is a signal that something went wrong. Build infrastructure to capture these signals and feed them back into your context layers.
This is the encode-deploy-tune loop: encode your institutional knowledge, deploy it as agent context, and tune it based on real-world usage. The organizations that build this loop see compound accuracy improvements over time.
The Relationship Between Text-to-SQL and Context Engineering
Many teams begin their analytics agent journey by focusing on text-to-SQL accuracy. This makes intuitive sense: if the agent can translate natural language into correct SQL, the problem seems solved. But text-to-SQL accuracy plateaus without context engineering, and the plateau arrives much sooner than most teams expect.
Consider the query: "Show me revenue by region for Q1." A text-to-SQL model might generate perfectly valid SQL that joins the right tables and groups by region. But without the Meaning layer, it does not know that your company's Q1 starts in February, that the APAC region was restructured last month, or that "revenue" should exclude internal transfers. The SQL is correct. The answer is wrong.
This is why 95% of analytics agents fail in production. The model generates plausible SQL, stakeholders get plausible-looking numbers, and nobody catches the subtle errors until a quarterly review reveals discrepancies. By then, trust is eroded and the agent is abandoned.
Text-to-SQL is a necessary component of any analytics agent. But it is one layer in a multi-layer system. Without the three-layer context architecture wrapping around it, even perfect SQL generation produces unreliable results.
Context Engineering and the Future of Analytics
The shift toward context engineering represents something larger than a technical practice. It is a fundamental reframing of what makes analytics work.
For the past decade, the industry focused on making data accessible: building warehouses, creating pipelines, deploying dashboards. Accessibility is solved. The bottleneck has moved upstream. The question is no longer "can I get to the data?" but "does the system understand what the data means at my company?"
This is why data democratization efforts have historically fallen short. Self-service analytics tools gave everyone access to dashboards, but dashboards only answer questions someone anticipated. The promise was that business users could explore data independently. The reality was that without contextual understanding, self-service produced more confusion than clarity.
Analytics agents have the potential to finally deliver on the self-service promise, but only if they are built on a foundation of structured context. An agent without context is just a faster way to get wrong answers.
Bottom line: Context engineering is not a feature to add to your analytics stack. It is the discipline that determines whether your analytics agent becomes a trusted resource or an expensive experiment. The organizations that invest in all three layers (Structure, Meaning, and Trust) will build agents that get smarter over time. Everyone else will join the 95% of failed POCs.
For teams evaluating how to put this into practice, platforms purpose-built for context engineering can compress the timeline from months of in-house development to weeks of structured deployment. The key is choosing infrastructure that treats context as the core product, not an afterthought.
Ready to Put Context Engineering Into Practice?
If your team has hit the accuracy wall with analytics agents, the diagnosis is likely a context problem, not a model problem. The three-layer architecture (Structure, Meaning, Trust) provides a systematic framework for closing the gap between demo-quality and production-quality answers.
For teams that want to accelerate the path from diagnosis to production, explore platforms designed for analytics context engineering that handle the infrastructure so your team can focus on encoding the institutional knowledge that makes agents trustworthy.
Frequently Asked Questions
What is context engineering for AI?
Context engineering is the practice of systematically curating, structuring, and delivering the institutional knowledge that an AI agent needs to produce accurate answers. For analytics agents, this means encoding schema metadata, metric definitions, business rules, tribal knowledge, and validated query patterns into a format the agent can reason over. Where prompt engineering focuses on how you ask the question, context engineering focuses on what the model knows before you ask anything at all.
Why do most analytics agents fail in production?
The short answer: missing context. Research consistently shows that the vast majority of AI pilots never graduate to production, and the root cause is rarely model quality. For analytics agents, the failure pattern is predictable. The agent writes syntactically valid SQL but returns semantically wrong answers because it does not understand how your company defines its metrics, which tables are authoritative, or what business rules apply. It looks right. It is not.
How is context engineering different from a semantic layer?
A semantic layer is one component of context engineering, specifically addressing the Meaning layer (metric definitions and business logic). Context engineering also includes the Structure layer (schema metadata, data lineage, table authority rankings) and the Trust layer (validated answers, correction history, usage signals). Many organizations treat their semantic layer as sufficient, but production agents also need to know which data sources are authoritative and which answers have been verified by human analysts. Think of the semantic layer as one important chapter in a much larger playbook.
What are the three layers of context for analytics agents?
Structure, Meaning, and Trust. Structure covers what data exists and how it connects: schemas, lineage, access controls, table freshness. Meaning covers what the data signifies at your specific company: metric definitions, business rules, fiscal calendars, tribal knowledge. Trust covers which answers have been validated and how the agent improves over time: golden queries, correction history, usage signals. All three layers are required for production-grade accuracy. Skipping any one of them introduces a category of errors that the other two cannot compensate for.
How did OpenAI build their internal data agent?
OpenAI's engineering team built an internal agent that serves thousands of employees across hundreds of petabytes and tens of thousands of datasets. The agent uses multiple context layers: table metadata and usage patterns, human annotations for semantic meaning, code-level data definitions, institutional knowledge from internal documents, and a memory system that stores corrections. A small team built it in a matter of months, and it reportedly saves hours per query. The biggest takeaway is that multi-layered context, not model size, is what made the agent trustworthy enough for company-wide adoption.
How long does it take to implement context engineering?
It depends on your starting point. Organizations that already maintain a semantic layer, documented metric definitions, and a data catalog can build a functional context layer in two to four weeks. Teams starting from scratch typically need six to twelve weeks for a minimum viable context layer covering their highest-priority use cases. The important thing to understand is that context engineering is a continuous practice, not a one-time project. The encode-deploy-tune loop means your context should improve with every user interaction, so starting imperfectly is far better than waiting for completeness.
Can I do context engineering without a semantic layer?
Yes. While a well-maintained semantic layer provides a strong foundation for the Meaning layer, it is not a prerequisite. Many organizations encode their institutional knowledge directly through structured documentation, validated SQL patterns, and metrics layer definitions without a traditional semantic modeling tool. The critical requirement is that the knowledge is structured and machine-readable, regardless of which tool manages it. If your team has metric definitions in spreadsheets, business rules in Confluence, and validated queries in analyst notebooks, you already have the raw material. The work is consolidation and structuring.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







