
Natural language queries make databases easier to ask, but trusted answers need business context, not just better text-to-SQL.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min

You have seen the demo. Someone types "what was revenue growth last quarter?" into a chat box, a chart appears in two seconds, and the room nods. Then a real stakeholder asks a real question against a real warehouse, and the same system confidently returns a number that is just plain wrong. Nobody notices until a decision has already been made on it.
A natural language query lets anyone ask a database a question in plain English instead of writing SQL. The system reads your intent, maps it to the right tables and metrics, runs the query, and hands back an answer. That part mostly works now. The part that breaks is quieter and more expensive: the system has no idea that "revenue" at your company means recognized ARR rather than run rate, or that your fiscal Q1 ends in April. It parsed every word perfectly and still missed the meaning.
If you lead analytics engineering, that gap is your problem to close, and it is not the gap most people think it is. The translation from words to SQL is largely solved, and the mechanics of that translation are worth understanding on their own. But translation accuracy is no longer where deployments live or die. This guide walks through how natural language queries actually work, the four stages where they succeed or fail, the difference between a one-off question and a real conversation, and the specific reason a flawless parser still returns wrong answers without business context.
Key Takeaways |
|---|
|
What Is a Natural Language Query?
A natural language query (sometimes shortened to NL query) is a request for information expressed in everyday human language rather than in a formal query language like SQL. Instead of writing SELECT SUM(amount) FROM orders WHERE created_at >= '2026-01-01', you type or say, "How much did we sell this year?" and the system does the translation for you.
The goal is straightforward: lower the barrier to data access. In their 2025 systematic review of natural language interfaces for databases (NLI4DB), Mengyi Liu and Jianqiu Xu frame this as democratizing data analytics, expanding querying to business analysts, domain experts, and decision-makers who lack advanced SQL training. The promise has been around since the 1960s. What changed recently is that large language models made the translation step dramatically better, moving natural language querying from a research curiosity to something teams actually try to deploy.
The core idea: A natural language query is not about replacing SQL. It is about removing the requirement that the person asking the question also be the person who can write the SQL.
It helps to separate the request from the machinery. This guide focuses on the natural language query interface, the layer the user touches and the reasoning that turns a question into a correct answer. The deeper plumbing of how a sentence becomes executable SQL, including where that pipeline tends to crack, is a subject of its own. Here, the focus is the practical experience: what a good natural language query system does, and what it takes to make the answers trustworthy.
How a Natural Language Query Actually Works
Behind a simple question sits a multi-stage process. Each stage is a place where the system can either get it right or quietly go wrong. Understanding these stages is the first step to diagnosing why your own natural language query tooling behaves the way it does.
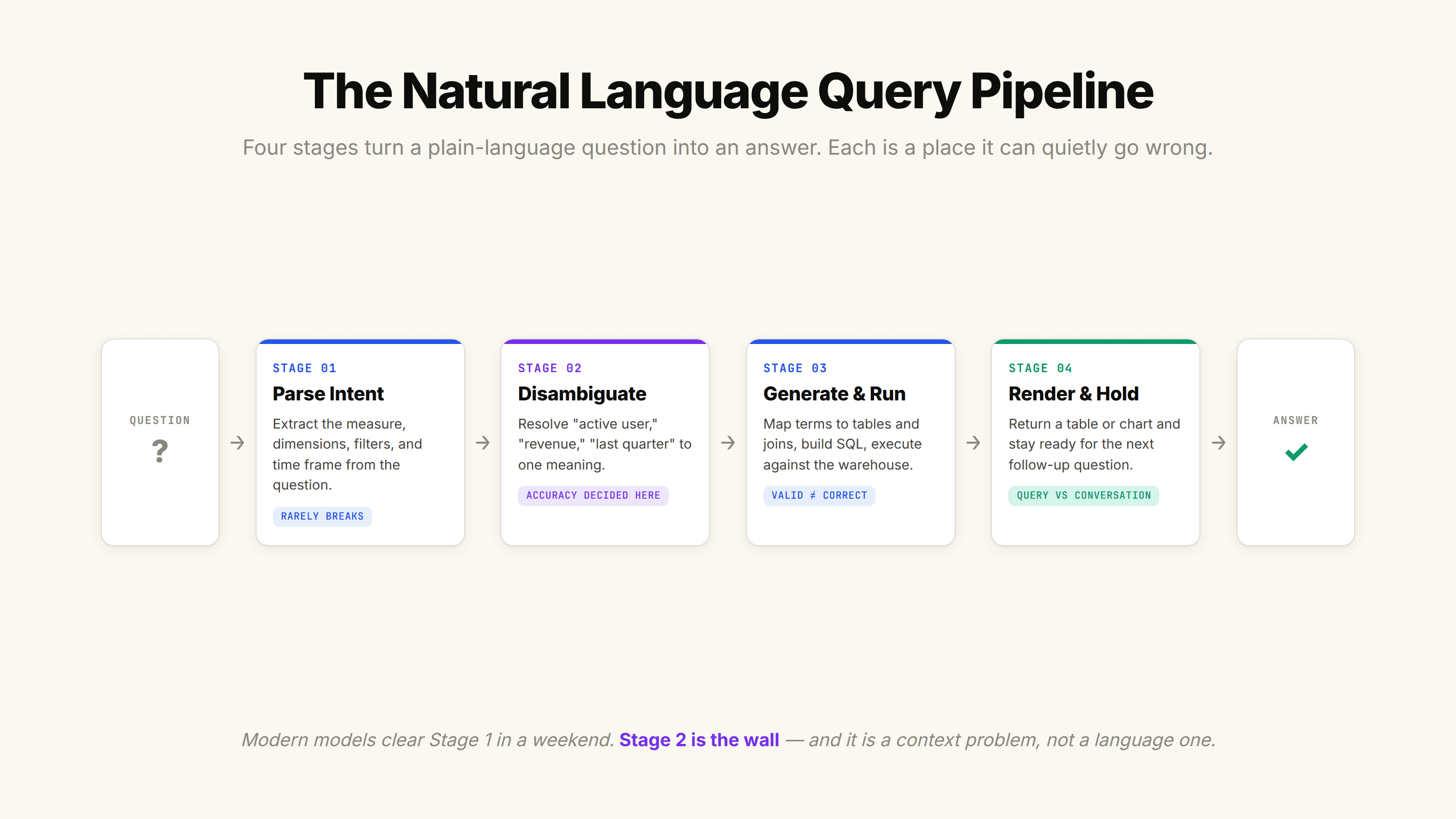
Step 1: Intent Parsing
First, the system has to figure out what you are actually asking. Intent parsing breaks your question into its analytical components: the measure (what you want to count or sum), the dimensions (how you want to slice it), the filters (which subset you care about), and the time frame.
Take "show me top customers by spend in Q2." The system needs to recognize that "top customers" implies a ranking, "spend" is the measure, and "Q2" is a time filter. This is where modern language models genuinely shine. They are good at extracting structure from messy, conversational phrasing. The reason this step rarely breaks anymore is that parsing language is exactly what these models were built to do.
Step 2: Disambiguation
Here is where things get interesting. Most real questions are ambiguous, and the system has to resolve that ambiguity before it can proceed.
Consider "show me active users." What does "active" mean? Logged in this week? Made a purchase this month? Has a non-cancelled subscription? The word is doing a lot of work, and the correct interpretation depends entirely on conventions inside your business. A natural language query system has three options when it hits this kind of fork:
Guess silently: Pick the most statistically likely interpretation and return an answer with no flag. This is fast and dangerous, because the user has no idea a decision was made on their behalf.
Ask a clarifying question: Surface the ambiguity ("Do you mean users who logged in, or users who made a purchase?") and let the user choose. User-in-the-loop mechanisms like this are one of the main ways to bridge the gap between technical accuracy and practical reliability.
Resolve from context: Look up the encoded definition of "active user" and apply it automatically, consistently, every time.
The third option is the only one that scales, and it is the one that requires something natural language alone cannot provide.
Step 3: Query Generation and Execution
Once intent is parsed and ambiguity resolved, the system maps your terms to actual database objects (tables, columns, joins) and generates an executable query. It runs against the warehouse and pulls the rows.
This is the stage people assume is the whole problem. It is not. The mechanics of mapping language to a schema and producing valid SQL are well-studied. For the purposes of this guide, the important point is that a syntactically perfect query can still return a meaningless answer, because correctness at this stage depends entirely on the decisions made in the two stages before it.
Step 4: Result Rendering and Follow-Up
Finally, the system returns the result, often as a table or chart, and, in better systems, stays ready for your next question. "Now break that down by region." "What about last year?" The ability to handle that follow-up without making you restate everything is the difference between a query tool and a conversation, which we will come back to.
Where Plain-English Querying Actually Delivers
Natural language querying is not hype. When the conditions are right, it delivers real, measurable value. In a 2025 controlled study, NYU researchers Panos Ipeirotis and Haotian Zheng had 20 data professionals run realistic business-intelligence tasks drawn from the BIRD benchmark, comparing a natural language interface against Snowflake's traditional SQL platform. The natural language system cut query completion times by 10 to 30 percent and lifted task success from 50 to 75 percent. The gains are real.
The pattern in where it works is consistent. Natural language queries succeed when:
The question is well-scoped and concrete: "How many orders shipped yesterday?" has one obvious interpretation and one correct answer.
The underlying terms are unambiguous: When "orders" maps cleanly to one table and "shipped" to one status, there is no semantic guesswork.
The data model is clean and the definitions are stable: A well-maintained schema with descriptive names gives the system fewer ways to go wrong.
The user can sanity-check the result: An analyst who knows roughly what the number should be can catch an off answer before it becomes a bad decision.
For a head of data drowning in repeat requests, this is the appeal. A large share of the analytics queue is the same handful of questions asked over and over. When those questions are concrete and well-defined, a natural language query layer can absorb them and free your team for work that actually needs a human. The trouble is that "concrete and well-defined" describes very few of the questions stakeholders actually ask.
Why a Perfect Parser Still Returns the Wrong Number
Now the uncomfortable part. The reason a natural language query demo looks magical and a production deployment frustrates everyone is that demos use clean, scoped questions and production gets the full, ambiguous, context-dependent mess of how real people ask for data.
The single clearest illustration comes from a16z's March 2026 analysis of why data agents fail. Picture a perfectly built system: modern foundation model, connected to all the right sources, nice UI. A user asks, "What was revenue growth last quarter?" A question so simple a glance at a Looker dashboard would answer it. And the system stalls, because:
Revenue is a business definition, not a database column. Is the user asking about run-rate revenue or ARR? Those are different numbers with different strategic meanings.
"Last quarter" is not normalized. Fiscal quarters vary by company. Your Q1 might be someone else's Q2. The system has no way to know your calendar from the schema alone.
The source of truth is unclear. Raw revenue might live across
fct_revenue,mv_revenue_monthly, andmv_customer_mrr. Which one is authoritative today?
None of these are language problems. The model parsed the sentence flawlessly. They are context problems, and they are exactly why translation accuracy has stopped being the bottleneck. As the a16z team put it, the market has realized that data and analytics agents are essentially useless without the right context. The model is good enough. What is missing is the institutional knowledge that tells it what your words mean.
This is the wall. Most natural language query projects clear the language hurdle in a weekend and then spend months stuck on the context hurdle, often without naming it as such.
This is also why benchmark scores can be misleading. The strongest models post high numbers on academic datasets like Spider, but as Georgia Koutrika notes in her ICDT 2024 survey of natural language data interfaces, those databases are low in complexity and general in subject matter. Real enterprise databases have hundreds of attributes, non-descriptive column names, and definitions that live in people's heads. Pair that with the double-digit real-world error rate the Ipeirotis and Zheng study flags as significant, and the stakes are clear: in a business-critical setting, a subtly wrong answer is worse than no answer, because someone will act on it. Understanding why accuracy plateaus, and the structured way to fix it, is the subject of context engineering for analytics agents.
NL Query vs. NL Analytics: A Critical Distinction
People use "natural language query" and "natural language analytics" interchangeably, and that conflation hides one of the most important distinctions in this space. They are not the same thing, and the difference determines whether your deployment feels like a vending machine or like talking to an analyst.
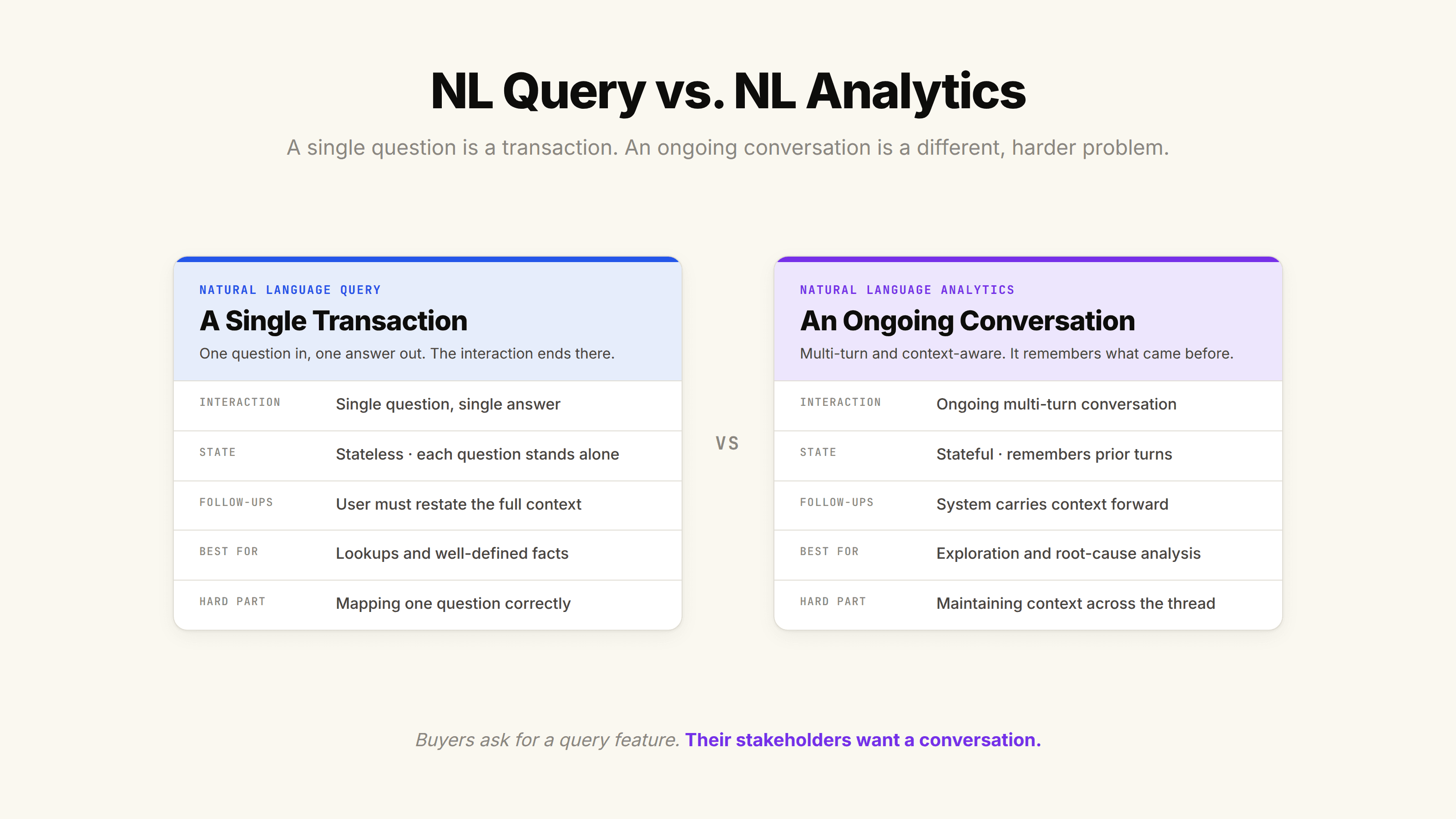
A Single Question Is a Transaction
A natural language query, strictly speaking, is one question and one answer. You ask, the system responds, the interaction ends. It is stateless. Each question stands alone. This is genuinely useful for lookups and well-defined facts, and it is where most first-generation tools live.
The limitation shows up the moment your question has a follow-up, which real analysis always does. You ask for revenue by region, you see something odd in one region, and you want to dig in. With a pure query tool, you start over and restate the entire context. That friction is exactly what pushes people back to pinging the data team.
An Ongoing Conversation Is a Different Problem
Natural language analytics is the conversation. It is multi-turn, stateful, and context-aware across the whole exchange. When you say "now break that down by region" and then "why did the West drop?", the system has to remember what "that" refers to and carry the thread forward.
This is a meaningfully harder engineering problem. The research community built dedicated benchmarks for it precisely because single-turn evaluation misses it. As a COLING 2020 survey of neural database interfaces documents, multi-turn corpora like SParC and CoSQL model the reality that users query data sequentially, each question understood in relation to what came before, and that a good system may need to ask its own clarifying questions back. The shift from question to conversation is the same shift that defines how natural language is replacing dashboard building altogether.
The table below lays out the practical difference.
Dimension | Natural Language Query | Natural Language Analytics |
|---|---|---|
Interaction | Single question, single answer | Ongoing multi-turn conversation |
State | Stateless, each question stands alone | Stateful, remembers prior turns |
Follow-ups | User must restate context | System carries context forward |
Disambiguation | Often a silent guess | Can ask and remember clarifications |
Best for | Lookups, well-defined facts | Exploration, root-cause analysis |
Hard part | Mapping one question correctly | Maintaining context across the thread |
The reason this distinction matters for you, specifically: most buyers think they want a natural language query feature when what their stakeholders actually want is an analyst they can have a back-and-forth with. Building the first and marketing it as the second is how trust erodes.
What It Takes to Make the Answers Trustworthy
If translation is solved and context is the gap, then making natural language queries trustworthy is fundamentally a context problem. The institutional knowledge that lives in Slack threads, in a dbt YAML last updated in 2021, and in the heads of your two most senior analysts has to be encoded somewhere the system can reach it. This is what we call context infrastructure, and it organizes into three layers.

Structure: What Data Exists
The system needs to know your schemas, tables, columns, relationships, and lineage. Which tables join to which, what each column actually holds, and which sources feed which. Without this, the system cannot find the right data even when it understands the question. Structure answers "what is there."
Meaning: What It Means Here
This is the layer that resolves "revenue" and "active user" and "last quarter." Metrics, KPIs, business rules, and definitions that are specific to your company. The semantic layer is part of this, but only part; encoded definitions, validated query patterns, and the tribal knowledge that has never been written down all belong here too. Meaning answers "what does this mean at our company," and it is the layer almost every tool underinvests in.
Trust: Which Answers Are Validated
The final layer is what separates a plausible answer from a verified one. Which queries have been checked by a human and marked correct? Which answers are golden? When the system has a library of validated patterns and usage signals, it can distinguish a guess from a known-good response, and it can improve over time as users correct it. Trust answers "can I rely on this."
Pro tip: When you evaluate any natural language query tool, ask which of these three layers it actually handles. Many handle Structure and a thin slice of Meaning. Very few handle Trust. The gap between a tool that does one layer and one that does all three is the gap between a demo and production.
The reason this framing matters: a natural language query system that nails parsing and SQL generation but skips the context layers will always plateau at the accuracy ceiling those layers impose. You cannot prompt your way past a missing definition of revenue. The knowledge has to be encoded, not inferred.
How to Evaluate a Natural Language Query Tool
When you are assessing options, the marketing will all sound identical: every tool promises you can ask questions in plain English and get instant answers. Cut through it with questions that probe the context layer, not the language layer.
Ask how it handles an ambiguous term. Hand it "show me active users" against an unfamiliar schema. Does it guess silently, ask, or apply an encoded definition? The answer tells you everything about production behavior.
Ask where definitions live. Can your team encode that "revenue means recognized ARR" once, and have every query respect it? Or is each query a fresh roll of the dice?
Ask about follow-ups. Run a real three-question sequence with pronouns and references. A tool that handles single questions but loses the thread is a query tool wearing an analytics costume.
Ask how it improves. When it returns a wrong answer and a user corrects it, does that correction make the next answer better, or does the same mistake recur forever?
Ask what it needs to start. Some tools require a fully built semantic model before they produce anything useful. Others can begin encoding context against your existing warehouse and validated queries without that prerequisite.
These are the questions that separate a tool that demos well from one that survives contact with your stakeholders. Once you know what to probe for, platform comparison stops being a feature-checklist exercise and starts reflecting how each tool behaves in production, across the full criteria of context handling, embedding, security, and multi-tenant support.
Three Ways Natural Language Querying Goes Wrong
Teams that struggle with natural language querying tend to stumble in the same few places. Each one traces back to treating a context problem as if it were a language problem.
1. Betting on a Bigger Model
The most common error is assuming a stronger model will fix accuracy. It will not, because the gap is context, not comprehension. Pouring effort into prompt engineering while the definition of your core metrics lives nowhere the system can read is treating the symptom and ignoring the disease.
How to avoid it: Audit where your definitions actually live before you evaluate any tool. If revenue is defined three different ways across three teams, that is your real project, not model selection.
2. Mistaking a Clean Demo for Production
Demos use curated questions. Production gets the messy, ambiguous, context-loaded reality of how people actually ask. A tool that aces a scripted walkthrough can still post the kind of double-digit real-world error rate that turns business-critical, the moment stakeholders bring their own questions.
How to avoid it: Test with your own ambiguous questions against your own schema, never the vendor's sandbox. Insist on a pilot with real users and real queries before you commit.
3. Letting the System Guess in Silence
A tool that resolves ambiguity invisibly will produce confident, wrong answers that nobody catches until a decision has already been made on bad data. This is the failure mode that erodes trust fastest, because the mistakes are invisible until they are expensive.
How to avoid it: Favor systems that either surface ambiguity or apply encoded, auditable definitions, so every answer can be traced back to a known rule.
The Bottom Line
Natural language querying is no longer bottlenecked by language. Modern models parse intent and generate SQL well enough that the headline problem has shifted entirely to context: knowing what your words mean inside your business. The "what was revenue growth last quarter?" example is not an edge case, it is the rule, and it is why a system that wins a demo can still lose a stakeholder's trust in week one.
For an analytics engineering lead, the takeaway is practical. Stop evaluating natural language query tools on how well they understand English and start evaluating them on how well they encode your institutional knowledge across Structure, Meaning, and Trust. That is the layer that determines whether the answers are trustworthy, and it is the difference between a feature that impresses and infrastructure your stakeholders can actually rely on. When you are ready to compare what is on the market against these criteria, the analytics agent platform buyer's guide is the place to start.
Frequently Asked Questions
What is a natural language query?
A natural language query is a request for data expressed in everyday language, such as "how many customers did we add last month?", instead of in a formal query language like SQL. The system parses the question, maps it to your data, runs the query, and returns the answer, letting non-technical users get data without writing code.
What is the difference between a natural language query and natural language to SQL?
Natural language to SQL is the specific technical step of translating a plain-language question into executable SQL. A natural language query is the broader user-facing experience that includes intent parsing, disambiguation, that translation step, execution, and result rendering. Natural language to SQL is one component inside the larger natural language query pipeline, not the whole of it.
Why do natural language query tools give wrong answers?
Most wrong answers come from missing context, not bad language understanding. The system can parse "what was revenue growth last quarter?" perfectly but still fail because it does not know how your company defines revenue, which fiscal calendar you use, or which table is the source of truth. These are semantic and business-context problems that language understanding alone cannot solve.
How accurate are natural language query systems?
On clean academic benchmarks, top systems score high, but on real business databases the picture changes: independent testing puts error rates in the 10 to 25 percent range, which is serious when wrong answers drive decisions. Accuracy depends far more on how well your business context is encoded than on the underlying model, which is why two teams using the same model can see very different reliability.
Can natural language queries handle follow-up questions?
A single natural language query is typically stateless and treats each question independently, so follow-ups require restating context. Handling a true multi-turn conversation, where "now break that down by region" carries forward the prior question, is the harder domain of natural language analytics, where the interaction becomes an ongoing exchange rather than a series of disconnected lookups.
Do I need a semantic layer to use natural language queries?
A semantic layer helps by encoding the Meaning layer (your metric and KPI definitions), but it is only one of three context layers a reliable system needs, alongside Structure and Trust. Some platforms require a fully built semantic model before they work, while others can begin encoding context against your existing warehouse and validated queries without that prerequisite.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







