
Learn what a semantic layer is, how it standardizes metrics, and why AI agents need it for trustworthy enterprise data answers.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min

A semantic layer is a business representation of data that sits between raw data sources and the tools or agents that query them, translating database tables and columns into consistent business concepts like "revenue," "active customer," and "monthly recurring revenue." It enforces a single definition of every metric across every dashboard, query, and analytics agent that touches your data. For most of the last decade, semantic layers were a governance nice-to-have. In the age of AI agents, they have become a prerequisite for trustworthy answers.
Key Takeaways |
|---|
|
What Is a Semantic Layer?
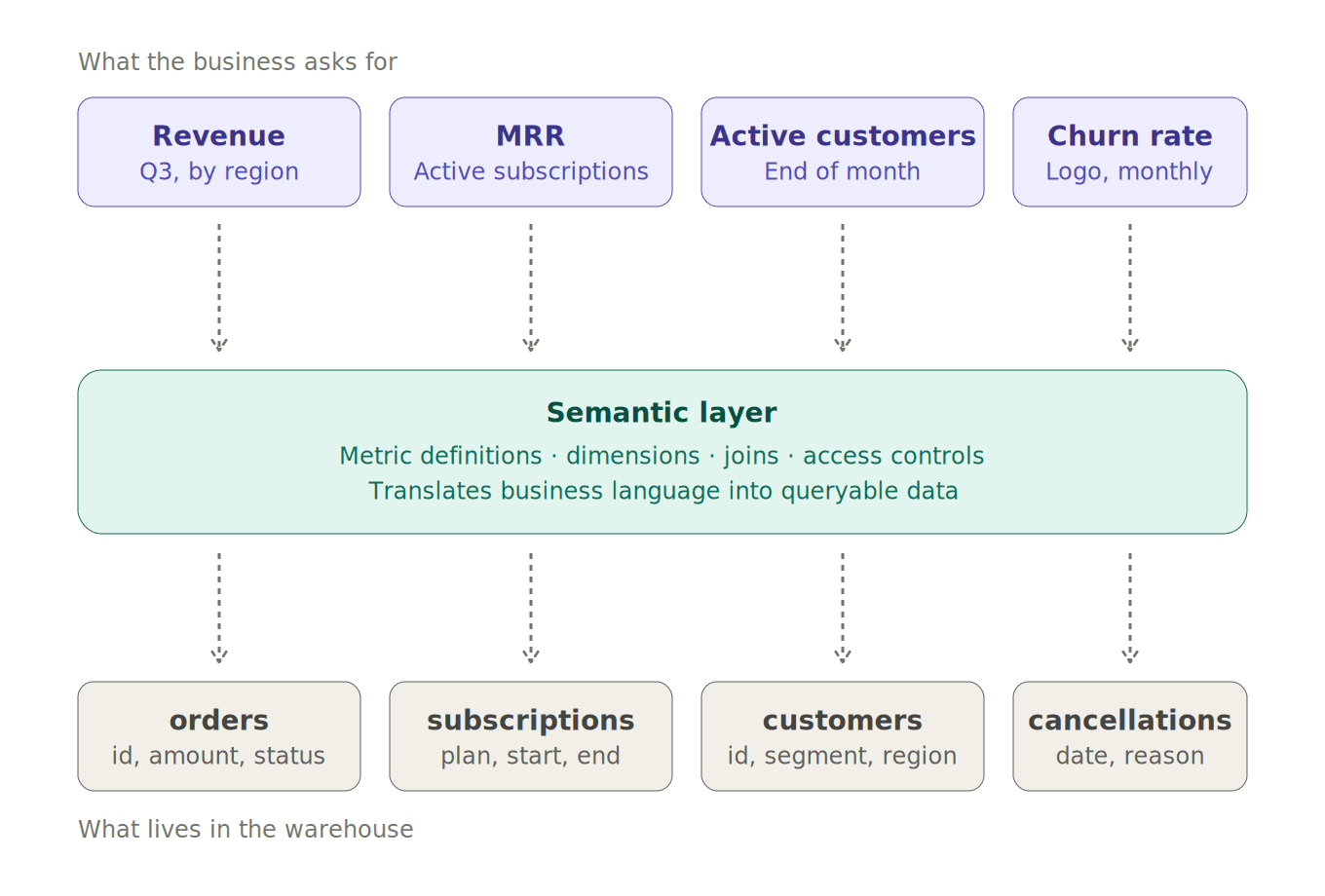
A semantic layer is an abstraction layer that sits between your data sources (warehouses, data lakes, OLAP cubes) and the consumers of that data (BI tools, dashboards, applications, analytics agents). Its job is to translate the technical reality of your data into a business reality.
In practice, this means three things. First, the semantic layer defines metrics, the quantitative measures your business runs on: revenue, gross margin, monthly active users, net retention, churn rate. Second, it defines dimensions, the slices you analyze metrics across: customer segment, product line, region, time period. Third, it defines the relationships between tables, so a query about "revenue by customer segment" knows which tables to join and how.
Think of it like a dictionary. Your raw warehouse holds tables called orders, customers, subscriptions, and cancellations. A business user does not care about those tables. They care about "monthly recurring revenue," "logo churn," and "expansion ARR." The semantic layer is the dictionary that maps the language of the business to the structure of the data.
Semantic Layer vs. Metrics Layer vs. Data Model
These terms overlap and often get used interchangeably, but there are real differences:
Data model: The schema and relationships of your underlying tables. The technical reality.
Metrics layer: A subset of the semantic layer focused specifically on metric definitions and calculations.
Semantic layer: The full business representation, including metrics, dimensions, hierarchies, joins, access controls, and natural-language descriptions.
For the purposes of this guide, "semantic layer" refers to the comprehensive business representation. For a deeper look at metric definitions specifically, see our guide on how the metrics layer fits in.
A Brief History (So You Know What's Actually New)
The concept is not new. Business Objects pioneered the "universe" in the 1990s, a semantic abstraction over relational databases. OLAP cubes encoded similar logic in the 2000s. Looker's LookML brought the idea into the modern cloud BI era in the 2010s, encoding metric definitions as version-controlled code.
What is new is the urgency. For two decades, semantic layers were optional. Teams could (and did) get by with metric definitions scattered across SQL files, dashboard configurations, and the heads of senior analysts. The cost was inconsistency: different dashboards showing different "revenue" numbers, executives debating definitions in board meetings, analysts spending hours reconciling reports.
That cost was tolerable. With analytics agents in the loop, it is not.
Why the Semantic Layer Suddenly Matters Again
The renaissance of the semantic layer is not driven by traditional BI. It is driven by AI agents that need to query data autonomously and return trustworthy answers.
Here is the problem. A large language model is excellent at translating natural language into SQL. Give a modern LLM a question like "show me revenue by region for Q3" and a schema with a few tables, and it will produce syntactically correct SQL most of the time. Benchmark studies on text-to-SQL accuracy regularly report 70-90% on academic datasets like BIRD and Spider.
But in production, those numbers collapse. Independent testing of 14 analytics agents by Claire Gouze found that real-world accuracy varies widely, with most agents failing on questions that require business context the schema alone does not provide.
Why? Because the agent does not know that at your company, "revenue" excludes refunds and partner discounts. Or that "active customer" means a customer with a paid subscription on the last day of the month, not the average across the month. Or that Q3 starts in November because your fiscal year is offset.
These are not SQL problems. They are context problems. And the semantic layer is precisely where this context lives.
The a16z and OpenAI Endorsement
In March 2026, Andreessen Horowitz published Your Data Agents Need Context, arguing that data and analytics agents are essentially useless without the right context layer feeding them. The piece named the semantic layer as a foundational component of agent context infrastructure.
A few months earlier, OpenAI published a writeup of its in-house data agent, used by 3,500+ employees across 600 PB of data. The team described multiple layers of context that the agent needs to operate reliably, with metric and dimension definitions sitting near the top of the stack.
The pattern is clear. Every team building an analytics agent at scale ends up reinventing the semantic layer, or wishing they already had one.
Key insight: The semantic layer is no longer a governance tool. It is the runtime context for every AI agent that touches your data. If you ship an analytics agent without one, you are asking an LLM to guess what your business means by every metric in every question. It will guess wrong often enough to break trust.
The Cost of Skipping It
Without a semantic layer, agents produce answers that are technically correct but semantically wrong. The SQL runs. The result returns. The number is presented confidently. The user has no way to know that the definition behind the number does not match what they meant.
This is the most dangerous kind of failure: an authoritative answer that no one can immediately verify. It erodes trust faster than no answer at all. Industry reports estimate that the vast majority of AI proof-of-concepts in analytics never reach production, and context failures of exactly this kind are a major contributor. For a deeper diagnosis, see our piece on why AI data agents fail in production.
Semantic Layer Architecture: How It Actually Works
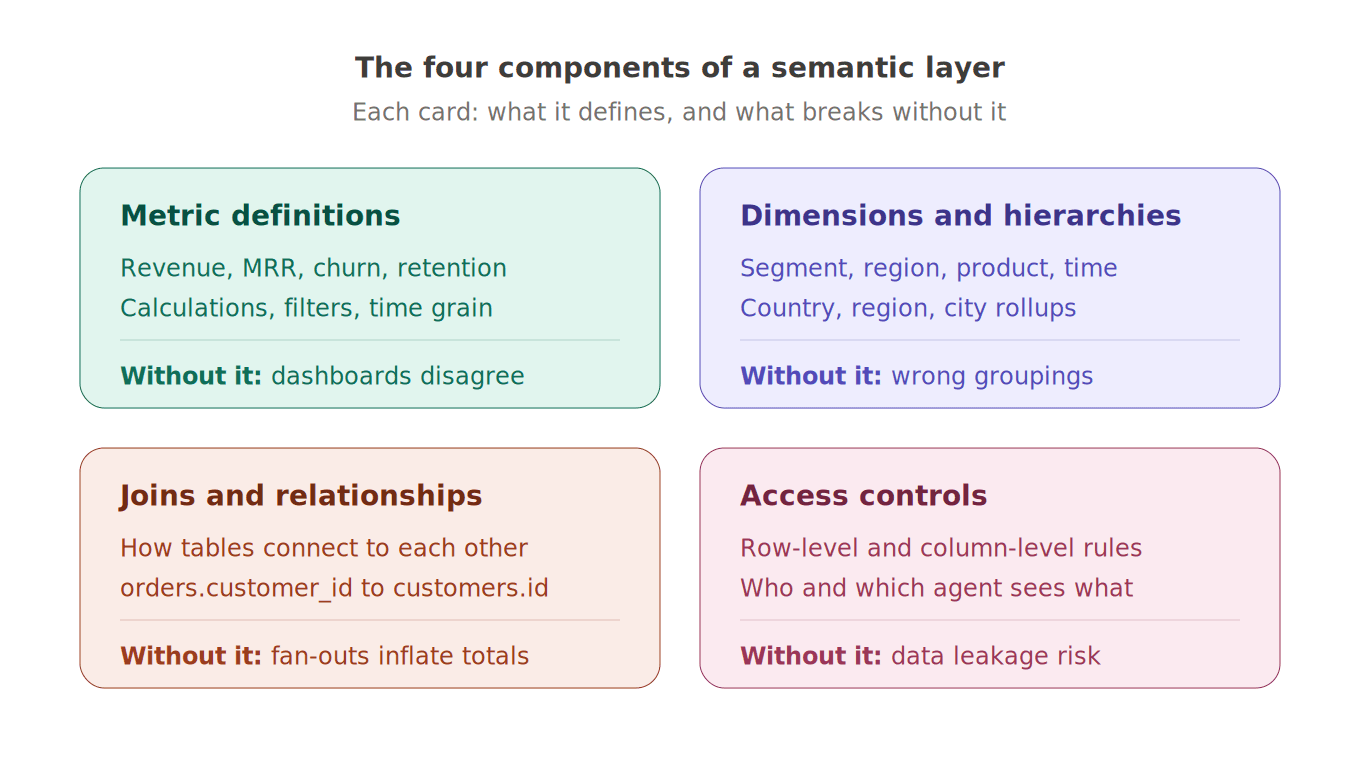
A modern semantic layer has four core components.
Component | What It Defines | What Breaks Without It |
|---|---|---|
Metric definitions | The calculation, filters, and grain of every business measure | Different dashboards return different numbers for the same metric |
Dimensions and hierarchies | The attributes and rollups used for slicing data | Agents pick the wrong grouping or invent dimensions that don't exist |
Joins and relationships | How tables connect to each other | Fan-out joins inflate numbers silently |
Access controls | Which users (and agents) can see which data | Compliance violations, data leakage, multi-tenant breaches |
1. Metric Definitions
Each metric is defined once, in code or YAML, and reused everywhere. A definition typically includes:
Name and description: "Monthly Recurring Revenue, the normalized monthly value of all active paid subscriptions."
Calculation: The aggregation logic (SUM, COUNT_DISTINCT, ratio of two measures, window function).
Source tables and columns: Which fields in which tables feed the calculation.
Filters: Business rules that scope the metric (exclude refunds, exclude internal accounts, restrict to billable line items).
Time grain: Whether the metric is computed daily, weekly, monthly.
Pro tip: Treat metric definitions like API contracts. Once published, breaking changes require deliberate versioning and communication. A silent change to your "revenue" definition can invalidate months of historical analysis and surface in a board meeting at the worst possible moment.
2. Dimensions and Hierarchies
Dimensions are the attributes you slice metrics by. A semantic layer defines them centrally, including any hierarchies (Country to Region to City) and time grain conversions (day to week to month to quarter to year). When an agent generates a "monthly revenue by region" query, the dimension definitions tell it which fields to group by and how to roll them up.
3. Joins and Relationships
The semantic layer encodes how tables relate. When an agent asks for "revenue by customer industry," the layer knows that orders joins to customers on customer_id, and customers has an industry column. The agent does not have to infer this from the raw schema, and it cannot accidentally invent a join that produces inflated numbers from a fan-out.
4. Access Controls
Mature semantic layers include row-level and column-level security: which users (or which agents acting on behalf of which users) can see which data. This is critical for multi-tenant SaaS analytics and any deployment touching regulated data (HIPAA, GDPR, financial compliance). The agent inherits these controls automatically.
Headless vs. Embedded Semantic Layers
There are two architectural patterns, and the distinction matters more in the agent era than it ever did before.
Embedded semantic layers live inside a BI tool. Looker's LookML, Power BI's tabular model, and Tableau's data model are all embedded. They serve that tool well but cannot easily share definitions across tools or expose them cleanly to external agents.
Headless semantic layers sit as a standalone service, exposing definitions via APIs (SQL, GraphQL, MCP). dbt's Semantic Layer, Cube, and AtScale fall in this category. They are the foundation of the modern agentic stack because any tool, application, or agent can query them consistently.
The Three-Layer Context Architecture: Where the Semantic Layer Fits
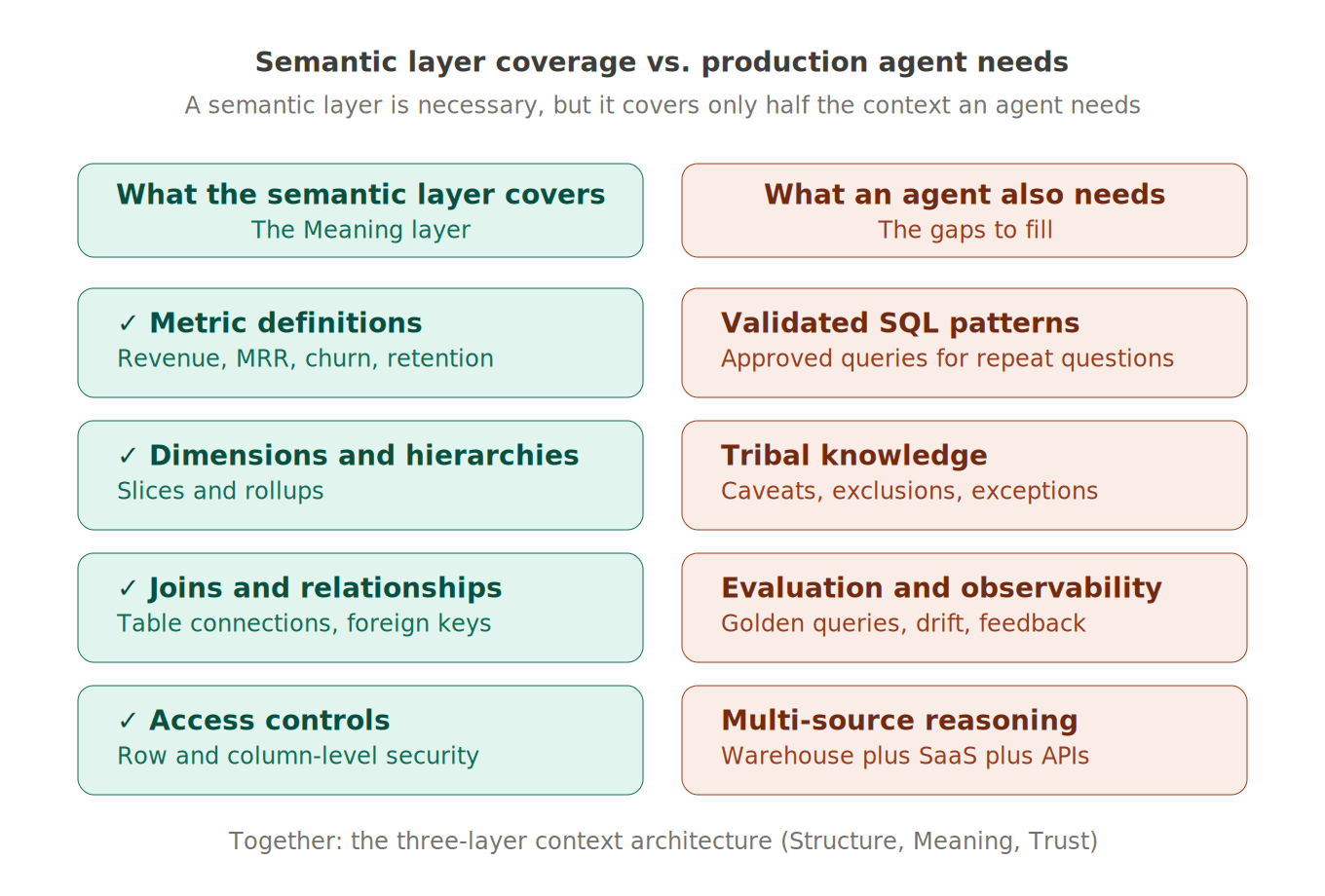
Here is the most important reframe in this guide, and the part most teams miss. A semantic layer is necessary but not sufficient for production-ready analytics agents. It is one of three layers an agent needs.
Layer 1: Structure (What Data Exists)
The Structure layer answers: what tables and columns are available, how they relate, what types they hold, what their freshness and quality signals look like, what their lineage is back to the source system. This is the warehouse, the data catalog, the lineage graph. Without it, the agent does not know what is queryable in the first place.
Layer 2: Meaning (What the Data Means at This Company)
The Meaning layer answers: what does "revenue" mean here, what counts as an "active user," how does the business define "churn," which customers belong to which segment, which time periods correspond to which fiscal quarters. This is the semantic layer.
The semantic layer is the Meaning layer. Without it, the agent generates SQL that runs but returns the wrong business answer.
Pro tip: When you audit your current setup, sketch the three layers on a whiteboard and mark which tool covers which layer. Most teams discover they have strong Structure (a good warehouse, decent lineage), partial Meaning (a semantic layer that covers a few dozen metrics), and effectively zero Trust (no captured golden queries, no evaluation harness, no usage signals fed back into the system). That gap is where production accuracy goes to die.
Layer 3: Trust (Which Answers Are Validated)
The Trust layer answers: which queries have been used and verified before, which answers have been corrected by analysts, which charts and metrics are considered "golden" within the organization, which questions have known caveats and edge cases. This is the layer that lets an agent learn from real usage and improve over time.
Context engineering for analytics agents is the discipline of building and curating all three layers together. The semantic layer covers one of the three. Most off-the-shelf semantic layer tools stop there, and that is exactly where production agents start running into accuracy ceilings.
Why This Matters for Tool Selection
When you evaluate a semantic layer tool, ask not just "does this define metrics well?" but "does this fit into a three-layer architecture?" A semantic layer that does not expose its definitions to agents via API, does not log how those definitions are used, and does not provide hooks for trust signals (verified queries, user feedback, evaluation results) will become a bottleneck the moment you try to deploy a serious agent on top of it.
What a Semantic Layer Cannot Do (Alone)
The semantic layer is essential. It is not the whole story. Here is what it does not solve.
Validated SQL Patterns
A semantic layer defines metrics declaratively. It does not store the specific SQL queries that real analysts have validated as correct for specific questions. When a user asks "what's our top-line growth rate," the agent benefits enormously from knowing that there is an approved query, written by a senior analyst, that has been used and corrected hundreds of times for exactly that question.
This is the difference between "the metric is defined" and "the answer is trusted." The semantic layer provides the former. Production context infrastructure provides both.
Tribal Knowledge
Some of the most important context at a company is not in any data model. It lives in Slack threads, in PRDs, in the analyst's head. For example:
"The September spike in churn was caused by a billing bug, not a real product issue. Exclude it from trend analysis."
"Sales reports MQLs differently than marketing does; for executive reporting, trust marketing's number."
"Don't include the 'internal' customer segment in any externally shared metrics."
"Our fiscal Q1 ends January 31, not March 31. Calendar Q1 is wrong."
A semantic layer is not designed to capture this kind of contextual nuance. Context infrastructure for agents needs to.
Evaluation and Observability
A semantic layer tells you how a metric is defined. It does not tell you whether the agent using that metric is producing accurate answers in production. For that, you need an evaluation harness: golden query testing, hallucination detection, drift monitoring, user feedback loops. How to evaluate an analytics agent is its own discipline. It depends on the semantic layer but extends well beyond it.
Multi-Source Reality
Most enterprises do not have a single warehouse. They have Snowflake plus Salesforce plus Stripe plus a half-dozen SaaS sources, with data living in different stores at different freshness. A traditional semantic layer is typically scoped to one analytical engine. Production agents have to reason across all of them, often joining warehouse data with SaaS API data in real time.
Building or Adopting a Semantic Layer: What to Consider
If you do not have a semantic layer yet, you have three realistic paths.
Path 1: Build It in dbt
dbt's Semantic Layer (powered by MetricFlow) is the most popular path for teams already using dbt for transformations. You define metrics in YAML, version-control them, and query them via the dbt Semantic Layer API. For details, see our deep dive on dbt's semantic layer implementation.
Strengths: Open standards, version control, integrates with your existing dbt workflow, growing ecosystem of consumers. Tradeoffs: Requires dbt expertise on the team; metric coverage starts small and grows over time; comparatively new (MetricFlow is still maturing).
Path 2: Use a Headless Semantic Layer Platform
Tools like Cube, AtScale, and similar headless layers provide a standalone semantic layer with broader connectivity and more out-of-the-box features. They are designed to serve multiple consumers (BI tools, custom apps, agents) consistently.
Strengths: Faster time to value, broader integrations, designed for multi-consumer use, often include caching and acceleration features. Tradeoffs: Another tool in your stack; pricing scales with usage; vendor lock-in to consider; modeling expertise still required.
Path 3: Use Context Infrastructure That Encodes Definitions Directly
Modern context infrastructure platforms can encode metric definitions, business rules, validated SQL, and trust signals directly, without requiring a separately maintained semantic layer first. This is the path teams take when they do not have a mature semantic layer but need to deploy an analytics agent quickly.
It is not a replacement for the semantic layer concept; the metric definitions still have to exist somewhere. But it can be a faster path to production for teams without an existing investment in dbt MetricFlow or Cube. It also has the advantage of capturing the other two layers (Structure and Trust) in the same place.
Coverage Strategy
Whichever path you take, do not try to model everything at once. Start with the metrics that drive the most repeated questions. Across customer deployments, we consistently see that a small portion of metrics drives the majority of recurring questions. Reducing your data team's ad-hoc request queue almost always starts with rigorous definitions for the top 10 to 20 questions.
Pro tip: Pick the metrics that account for roughly 80% of the questions your team gets asked. Define those rigorously, with explicit filters, time grain, and edge cases documented. Expand from there. Trying to model the entire business at once is the most common reason semantic layer projects stall before they ship anything useful.
Common Semantic Layer Mistakes in the Agent Era
Even teams with mature semantic layers run into problems when they try to deploy analytics agents on top. Here are the patterns we see repeatedly.
1. Treating the Semantic Layer as a Governance Tool Only
The semantic layer was traditionally maintained for human consumers: dashboards, scheduled reports, BI users. The definitions were written for humans to read in a UI. They often lack the precision (and the metadata) that an agent needs to use them correctly. A description that reads "revenue per customer" is fine for a human looking at a tooltip. An agent will not know whether to use total revenue, net revenue, or recognized revenue.
Fix: Audit your metric definitions for agent readability. Are descriptions unambiguous? Are filters explicit? Are time grain rules documented? An agent will take your definitions literally and silently.
2. No Validated Query Layer
A perfectly defined metric is not the same as a known-good query. Agents benefit from seeing examples of correct queries paired with the questions they answer. Without this, the agent has to reinvent SQL every time, and small variations in phrasing can produce divergent results for the same underlying question.
Fix: Capture validated queries as first-class artifacts in your context infrastructure. Pair each with the question it answers and the metric it draws on. Treat them as part of the Trust layer.
3. No Observability on Agent Usage
If you do not log how the agent uses your semantic layer, you cannot improve either one. You cannot tell which metrics are being queried, which definitions are confusing the agent, which questions repeatedly fail or get clarified.
Fix: Instrument the agent's usage of the semantic layer end to end. Every query, every metric resolution, every user follow-up should be logged and reviewable. This is the feedback loop that makes accuracy compound over time.
4. Assuming the Semantic Layer Is Enough
This is the meta-mistake. A semantic layer is necessary but not sufficient. Teams that ship an agent on a semantic layer alone (and skip the Trust layer entirely) find that accuracy plateaus around 70-80% and stays there. The gap to production-grade accuracy comes from validated queries, evaluation harnesses, and continuous learning from real user feedback.
Fix: Treat the semantic layer as one of three layers, not as the finished context infrastructure. Plan from day one for how the Trust layer will be captured, governed, and exposed to your agent.
Who Owns the Semantic Layer?
A practical question that gets political fast: who is responsible for maintaining the semantic layer once you have one?
In most organizations, ownership lands with analytics engineering, the team that already owns dbt models, data quality, and lineage. This is usually the right call. Analytics engineers have the SQL fluency, the testing discipline, and the proximity to source data that semantic layer work requires.
But in the agent era, the semantic layer is no longer just a data infrastructure artifact. It is a product surface. Business stakeholders consume it through natural language. Product managers need to influence which metrics get prioritized. Security and compliance teams need to review access controls. The good news is that modern semantic layer tools (and context infrastructure platforms) increasingly support multi-stakeholder workflows: analytics engineers own the canonical definitions, while business owners can suggest changes, flag ambiguities, and approve their domain's metrics.
The bottom line: own it in analytics engineering, but design the workflow so the rest of the business can contribute without bottlenecking on a single team.
Pro tip: Set up a quarterly "metric review" ritual where stakeholders from sales, finance, product, and customer success can flag definitions that no longer match how their team thinks about the business. Most semantic layers decay because no one is responsible for noticing when the business has moved on from a definition that was correct two years ago.
What Changes When You Add an Agent
The ownership question gets sharper when an agent enters the picture. With dashboards, a wrong metric definition produces a wrong number on one chart that someone might notice in a weekly review. With an agent, a wrong definition produces wrong answers to hundreds of questions a day, each delivered confidently in natural language, each potentially being copied into a deck or a Slack message before anyone catches it.
This is why semantic layer maintenance is shifting from "annual cleanup project" to "continuous discipline." The cost of a bad definition has gone up by orders of magnitude. Teams that recognize this early invest in tooling for definition versioning, change review, and impact analysis. Teams that do not, learn the hard way.
See How Modern Platforms Use the Semantic Layer
If you are evaluating analytics agent platforms, the semantic layer integration story is one of the most important things to test. The best platforms treat the semantic layer not as a one-time import but as living context that evolves with how users actually query data, captured alongside validated queries and trust signals in a unified context infrastructure. For a deep look at what to evaluate, see our guide to AI agent builder platforms for analytics.
Frequently Asked Questions
What is the difference between a semantic layer and a data warehouse?
A data warehouse stores the raw data and its schemas. A semantic layer sits on top, mapping technical tables and columns to business concepts like metrics and dimensions. The warehouse answers "what data exists." The semantic layer answers "what does this data mean to the business." Both are required; neither replaces the other.
Is the semantic layer the same as a metrics layer?
The metrics layer is a subset of the semantic layer focused specifically on metric definitions and calculations. The full semantic layer also includes dimensions, hierarchies, joins, access controls, and descriptions.
Do I need a semantic layer to deploy an analytics agent?
You need somewhere for institutional context (metric definitions, business rules, tribal knowledge) to live, but it does not have to be a traditional semantic layer tool. Modern context infrastructure platforms can encode this knowledge directly. The principle (context must exist somewhere structured) is mandatory. The specific tool is not.
Which semantic layer tool is best?
It depends on your stack and use case. dbt's Semantic Layer is the default choice for teams already using dbt. Cube is strong for multi-source, multi-consumer deployments and was an early mover in agentic analytics. Embedded semantic layers (Looker LookML, Tableau data model) work well within their respective tools but do not extend cleanly to external agents.
How long does it take to build a semantic layer?
Defining the first 10 to 20 critical metrics typically takes a few weeks for an analytics engineering team. Comprehensive coverage of a business takes months to years and is never truly "done." The right strategy is to ship the high-value metrics first and expand iteratively, rather than waiting for completeness.
Why are analytics agents making semantic layers more important?
Because LLMs can generate technically correct SQL without knowing what your business actually means by "revenue" or "active customer." Without a semantic layer (or equivalent context infrastructure), agents return authoritative-sounding answers that may be semantically wrong. Both a16z's analysis of data agents and OpenAI's own data agent writeup identify metric and definition context as foundational to agent reliability.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







