
Why do AI data agents fail in production? Learn how missing context, not bad models, causes inaccurate answers, lost trust, and stalled pilots.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min

Your data agent demo was flawless. Leadership was impressed. The proof of concept answered natural language questions with clean charts and confident summaries. Then you deployed it to real users, and everything fell apart. Revenue numbers came back wrong. Definitions shifted between queries. Business users lost trust within a week.
You are not alone. According to MIT's Project NANDA research, 95% of generative AI pilots fail to deliver measurable business impact. For analytics agents specifically, the failure mode is almost always the same: the model works fine, but the context is missing.
This article is a diagnostic guide. If your team has built (or tried to build) an analytics agent and hit the wall, this will help you understand exactly what went wrong, why it happened, and what the structured path forward looks like.
Key Takeaways |
|---|
|
Why the Demo Worked but Production Didn't
Every failed analytics agent shares a similar origin story. A small team connects an LLM to a data warehouse. They test it on a handful of questions they already know the answers to. The results look impressive. Then deployment happens, and the real questions begin.
This is where the gap between demo and production becomes visible. In the demo, the team implicitly supplies context: they know which tables matter, what "revenue" means at this company, and which edge cases to avoid. The agent appears intelligent because the humans around it are doing the hard work of interpretation.
In production, that implicit context vanishes. A sales director asks about quarterly revenue, and the agent pulls from a staging table instead of the finance team's canonical source. A product manager asks about churn, and the agent defines it differently than the customer success team does. A finance analyst asks about ARR, and the agent confuses it with run rate.
In fact, a16z's analysis of enterprise data agents captures this precisely: over the past year, organizations realized that data and analytics agents are fundamentally unable to function without the right context. They cannot parse vague questions, resolve business definitions, or reason across disparate data effectively.
The core insight: Your agent did not fail because the model is bad. It failed because nobody encoded the institutional knowledge that makes your data meaningful.
The 95% Failure Rate: What the Data Actually Shows
The numbers tell a consistent story across multiple research sources.
MIT's Project NANDA surveyed over 300 AI deployments and found that only about 5% of organizations achieved rapid revenue acceleration from their generative AI initiatives. The rest stalled, delivering little to no measurable impact.
Gartner predicts that through 2026, organizations will abandon 60% of AI projects that lack AI-ready data. Their survey of data management leaders found that 63% of organizations either do not have or are unsure if they have the right data management practices for AI.
IDC research found that 88% of AI POCs do not make it to production. For every 33 AI POCs a company launched, only four graduated to deployment.
And Gartner's January 2026 analysis confirmed that by the end of 2025, at least 50% of generative AI projects were abandoned after proof of concept due to poor data quality, inadequate risk controls, escalating costs, or unclear business value.
These are not fringe findings. They represent the consensus across every major research firm studying enterprise AI adoption. The pattern is clear: the technology works in isolation, but it breaks when it meets organizational reality.
Why Analytics Agents Are Especially Vulnerable
General AI use cases like content generation or code assistance have a built-in advantage: humans review every output before it matters. If ChatGPT writes a mediocre email, someone rewrites it.
Analytics agents do not have that safety net. When a CFO asks for quarterly revenue and gets a number, that number goes into a board deck. When a product manager asks about feature adoption and gets a chart, that chart shapes a roadmap decision. The tolerance for error is effectively zero, and the consequences of wrong answers compound silently.
This is why the failure rate for analytics agents is arguably higher than the broader AI failure statistics suggest. The stakes are higher, the accuracy requirements are stricter, and the context required is deeper.
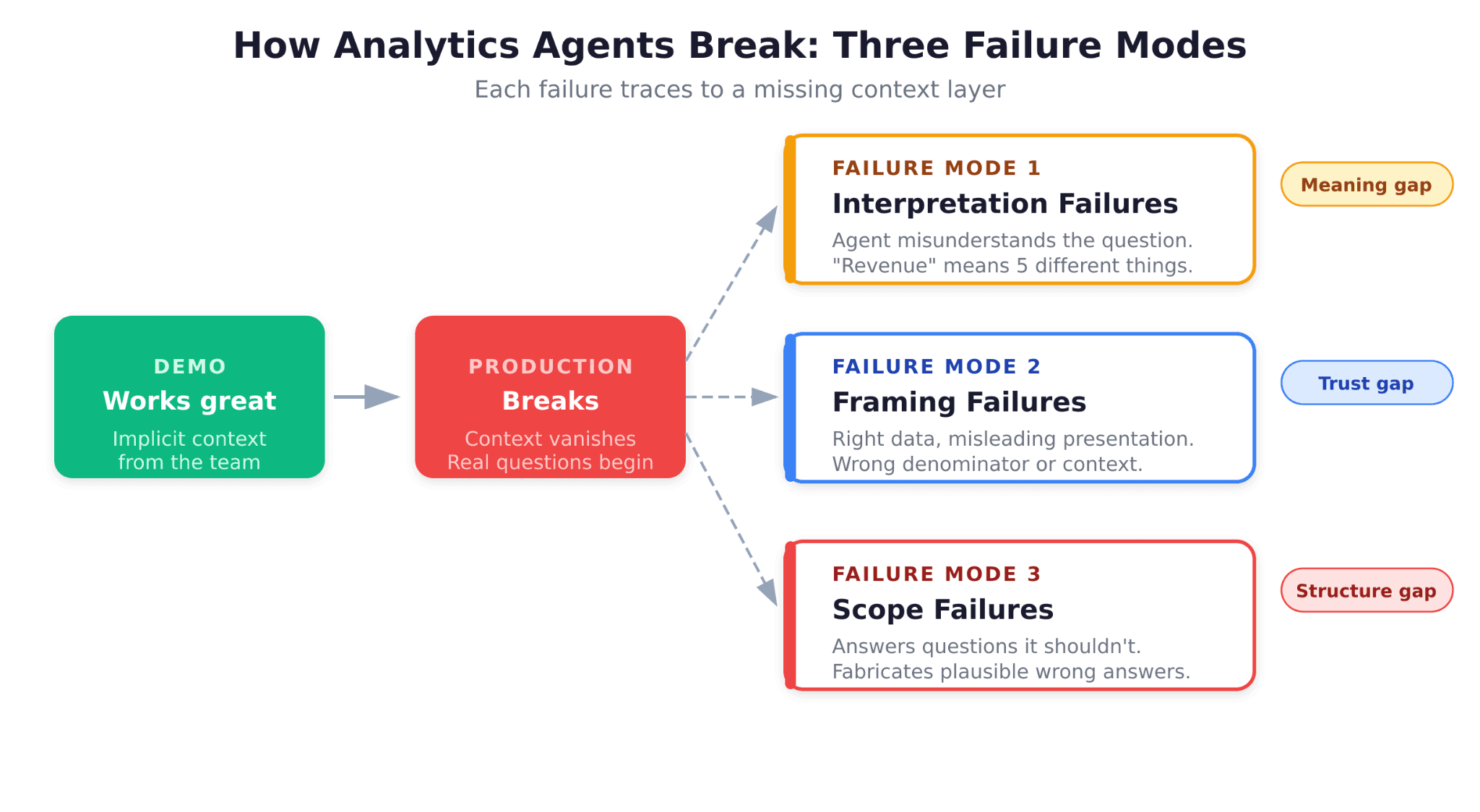
A Failure Taxonomy: The Three Ways Analytics Agents Break
After studying why these projects fail, a clear taxonomy emerges. Analytics agents do not break randomly. They break in predictable, diagnosable ways.
Failure Mode 1: Interpretation Failures
The agent misunderstands what the user is asking. "Show me revenue" could mean gross revenue, net revenue, ARR, MRR, or recognized revenue, depending on who is asking and in what context. Without encoded business definitions, the agent guesses, and guesses wrong.
This is the most common failure mode and the hardest to detect, because the agent returns a confident answer that looks correct. The SQL executes cleanly. The chart renders beautifully. But the number is wrong because the agent interpreted "revenue" differently than the user intended.
Failure Mode 2: Framing Failures
The agent finds the right data but presents it in a misleading way. It calculates churn correctly but uses the wrong denominator. It shows month-over-month growth but does not account for seasonality. It compares two time periods that are not actually comparable.
Framing failures are the domain of experienced analysts: the people who know that a raw number without context can be more dangerous than no number at all. When an agent lacks this institutional knowledge, it produces technically correct but practically misleading answers.
Failure Mode 3: Scope Failures
The agent tries to answer a question it should not attempt. Maybe the data does not exist in the warehouse. Maybe the answer requires joining data from systems the agent cannot access. Maybe the question involves a business concept that has not been defined anywhere.
The most dangerous version of this failure is when the agent does not recognize its own limitations. Instead of saying "I don't have enough information to answer this," it fabricates a plausible response using whatever data it can find.
Pro Tip: If your agent is failing in production, start by categorizing failures into these three buckets. The fix for each is different, and knowing which failure mode dominates will shape your remediation strategy.
The Two Dimensions of Accuracy
Most teams evaluating analytics agents focus on a single question: "Did the SQL query return the right data?" This is necessary but insufficient. There are actually two distinct dimensions of accuracy, and both must be solved.
Technical Accuracy: Is the SQL Correct?
Technical accuracy measures whether the generated SQL queries the right tables, applies the right joins, filters the right conditions, and returns the right rows. This is what benchmarks like BIRD and Spider measure, and it is where most of the industry's attention has focused.
Modern LLMs have made significant progress here. Given a well-documented schema, frontier models can generate technically correct SQL for a wide range of queries. But technical accuracy alone does not solve the production problem.
Semantic Accuracy: Does the Answer Mean What It Should?
Semantic accuracy measures whether the answer is meaningful in context. Does "revenue" match the finance team's definition? Does "active user" align with the product team's criteria? Does "last quarter" refer to the fiscal quarter or the calendar quarter?
This is where most analytics agents fail. As the a16z analysis illustrates with a simple example: an agent asked about quarterly revenue growth may find a revenue table and calculate growth. But if the semantic layer was last updated by a team member who left the company, and it does not include two new product lines launched since then, the answer is technically correct SQL executed against semantically incorrect context.
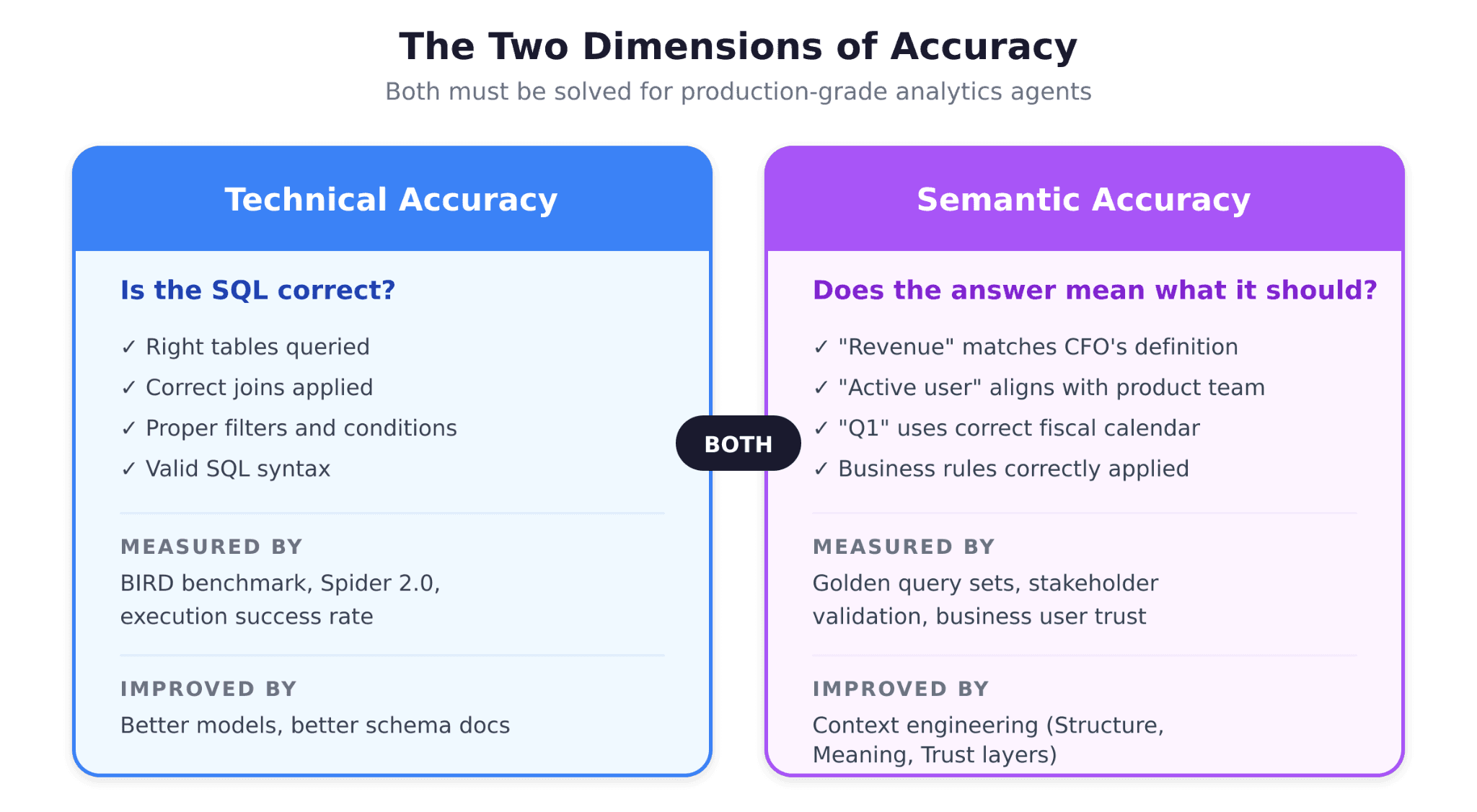
The distinction matters because the solutions are different. Technical accuracy improves with better models and better schema documentation. Semantic accuracy requires something fundamentally different: encoded institutional knowledge.
What OpenAI Learned Building Their Own Data Agent
OpenAI's experience building an internal data agent is one of the most instructive case studies available. As documented in their engineering blog post, a small team built a production agent in three months that is now used company-wide.
The metaphor that captures their key insight: giving a new analyst database access on their first day versus their sixth month. On day one, they can write SQL. By month six, they understand which tables are trustworthy, which metric definitions are current, which edge cases matter, and which stakeholders care about which numbers.
The difference is not skill. It is context. OpenAI's agent works because the team built that "month six knowledge" into the system itself, through layered metadata, human annotations, institutional documentation, and a memory system that learns from corrections over time.
Why the a16z Analysis Matters for Your Team
In March 2026, a16z published "Your Data Agents Need Context," which crystallized what many data teams had been experiencing firsthand. The analysis traces the evolution from the modern data stack to the agent frenzy to what they call "hitting the wall."
The a16z framework identifies a crucial gap: a traditional semantic layer, while valuable, is not sufficient for agent-driven analytics. Semantic layers handle metric definitions, but agents need more: canonical entities, identity resolution, tribal knowledge instructions, governance guidance, and continuously updated context that reflects how the business actually operates today.
This aligns with what practitioners are discovering independently. Claire Gouze's benchmark of 14 analytics agents tested a seemingly simple question: "What's the percentage of users who churned last month?" The question required joining three tables, understanding that one subscription can include multiple users, and calculating churn against last month's paying users rather than this month's. Most agents failed, not because of SQL limitations, but because they lacked the context to interpret the question correctly.
The Three-Layer Context Architecture: A Structured Fix
If the problem is missing context, the solution is structured context engineering. This means encoding the institutional knowledge that makes analytics accurate into a format agents can use. The approach requires three distinct layers:
Layer 1: Structure (What Data Exists)
The Structure layer captures schemas, tables, column definitions, lineage, relationships, and usage patterns. It answers the question: "What data do I have, and how does it connect?"
Most organizations have some version of this in their data catalog or dbt documentation. The problem is that it is often incomplete, outdated, or disconnected from the agent's context window. For an analytics agent to work reliably, the Structure layer must be continuously maintained and directly accessible to the agent at query time.
Layer 2: Meaning (What the Data Represents)
The Meaning layer captures metric definitions, KPI formulas, business rules, and the tribal knowledge that determines how data should be interpreted. It answers the question: "What does 'revenue' mean at this company, right now?"
This is where most agents fail. The Meaning layer is the semantic layer plus everything a semantic layer typically misses: the exceptions, the edge cases, the "everyone knows that" knowledge that lives in Slack threads and the heads of senior analysts. As the a16z analysis notes, a modern context layer should become a superset of what a traditional semantic layer covers.
For a deeper dive into how to build and maintain the Meaning layer, see our guide on context engineering for analytics agents.
Layer 3: Trust (Which Answers Have Been Validated)
The Trust layer captures verified answers, golden query sets, user corrections, and usage signals. It answers the question: "Which answers have been confirmed as correct by humans?"
This is the layer that almost every analytics agent implementation ignores, and it is arguably the most important for production reliability. Without the Trust layer, there is no mechanism for the agent to improve over time. With it, every user interaction becomes a potential feedback signal that compounds accuracy.
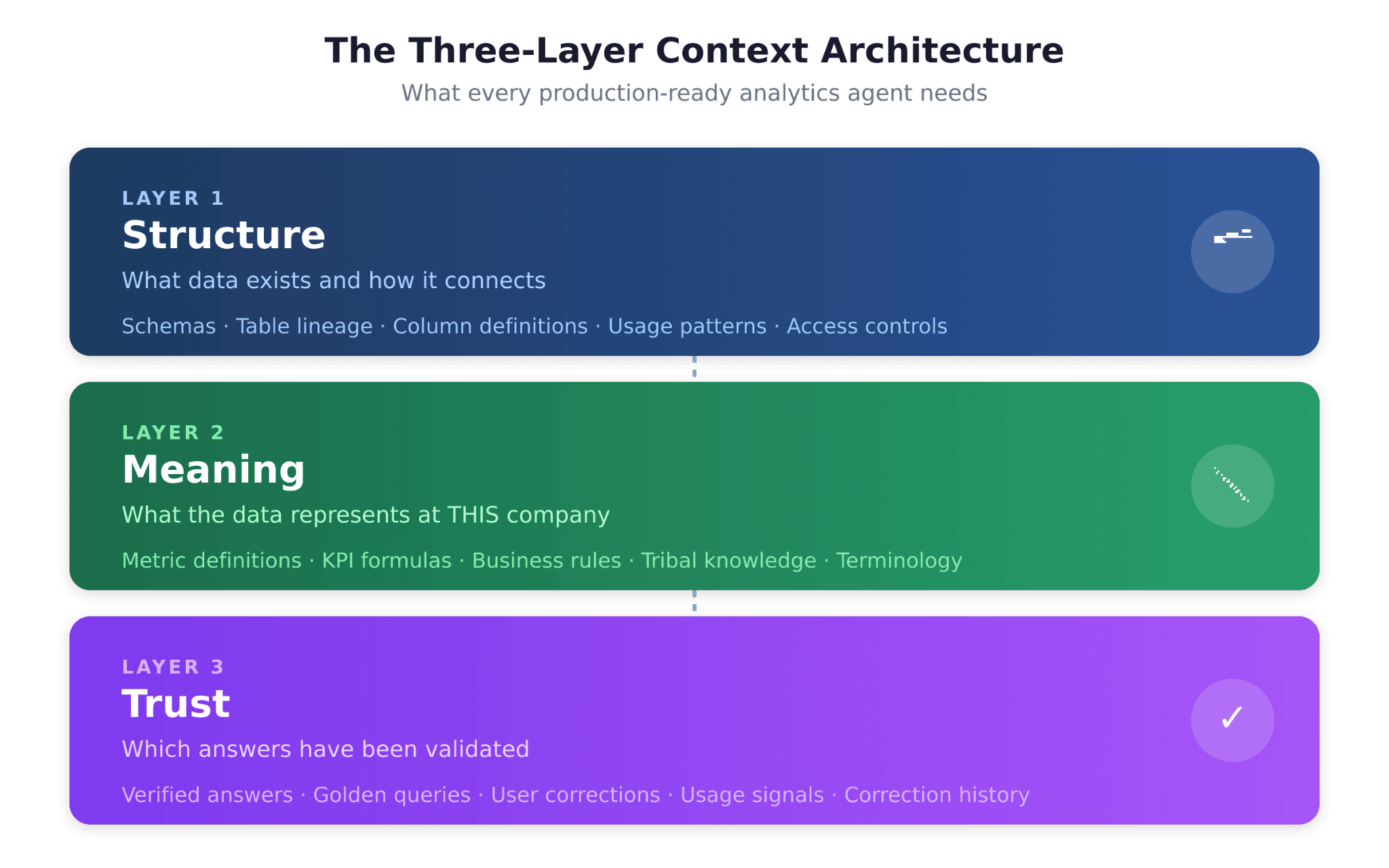
Most competitors and in-house builds solve one or two of these layers. The Structure layer is table stakes. Some address the Meaning layer through semantic layer integrations. Almost none systematically address the Trust layer.
Bottom line: If your agent has failed in production, diagnose which layer is missing. Interpretation failures point to gaps in the Meaning layer. Framing failures suggest missing Trust layer signals. Scope failures indicate Structure layer gaps.
The Path from Failed POC to Production
If your team has already tried and failed, here is the diagnostic framework for moving forward.
Step 1: Categorize Your Failures
Pull the last 50 failed queries from your agent. Classify each as an interpretation failure, framing failure, or scope failure. This distribution tells you where to focus.
Step 2: Assess Your Context Layers
For each layer (Structure, Meaning, Trust), evaluate what exists today:
Layer | What to Assess | Common Gap |
Structure | Schema documentation, table lineage, column descriptions | Incomplete or outdated catalog entries |
Meaning | Metric definitions, business rules, KPI formulas | Definitions exist but are stale or inconsistent |
Trust | Verified queries, golden datasets, user feedback loops | Usually nonexistent |
Step 3: Decide Build vs. Buy
The honest truth is that building a production-grade context layer is hard. OpenAI's internal agent was built by two engineers in three months, but OpenAI has world-class data infrastructure and direct access to frontier models. Most organizations do not.
MIT's research found that purchased, vendor-led AI solutions succeed about 67% of the time, while internal builds succeed only about one-third as often. This does not mean building is wrong; it means building requires honest assessment of your team's capacity, your data infrastructure maturity, and your timeline.
Step 4: Implement Evaluation Infrastructure
You cannot improve what you cannot measure. Before fixing your agent, build the evaluation infrastructure to track accuracy over time:
Golden query sets: A curated set of questions with known correct answers, tested on every deployment
Failure mode tracking: Automated classification of failed queries by type
User feedback loops: Mechanisms for business users to flag incorrect answers
Accuracy trending: Weekly or monthly accuracy metrics across query categories
For detailed evaluation frameworks, see our guide on how to evaluate analytics agents systematically.
Step 5: Build the Context Layer Incrementally
Do not try to encode all institutional knowledge at once. Start with the 20% of context that covers 80% of queries. Identify the ten most-asked questions, ensure those are perfectly accurate, and expand from there.
This is what context engineering for analytics looks like in practice: a continuous loop of encoding context, deploying agents, measuring accuracy, and refining based on real user interactions.
Three Fixes Teams Try After a Failed Agent (and Why They Don't Work)
If your team is debating next steps after a failed analytics agent deployment, three approaches come up repeatedly. Two of them are dead ends.
"We just need to upgrade the model." Consider a concrete example: your agent is asked "What was revenue last quarter?" A frontier model generates syntactically perfect SQL, pulls from a revenue table, and returns a number. The number is wrong because the agent used gross revenue instead of ARR excluding professional services, and it used calendar Q1 instead of your fiscal Q1 which starts in February. Swapping GPT-4 for GPT-5 does not fix this. The model was never the problem. The missing metric definition was.
"We don't have time to document all our business rules." You do not need to document all of them. Start with the ten questions your team gets asked most often. Pull the last month of Slack requests to your analytics team and identify the repeat queries. Encode the context for those ten questions: which tables to use, how the metrics are defined, what edge cases to exclude. That covers the majority of real-world usage. Expand from there. Context engineering is incremental, not waterfall.
"Our semantic layer should handle this." It handles part of it. A well-maintained semantic layer gives you the Meaning layer: metric definitions, KPI formulas, business logic. But your agent also needs to know which of your five revenue tables is the canonical source (Structure) and whether its answers match the numbers your CFO approved last quarter (Trust). A semantic layer is one chapter in a three-chapter book.
Moving Forward: From Diagnosis to Action
The 95% failure rate is not a death sentence for analytics agents. It is a diagnosis. The technology works when the context is right. The organizations that succeed are the ones that treat context engineering as a first-class discipline, not an afterthought.
If your team has hit the wall, the path forward is not to try harder with the same approach. It is to step back, diagnose which context layers are missing, and build the infrastructure to fill those gaps systematically.
For teams ready to take the next step, start with our definitive guide on the context engineering approach to fixing agent accuracy, which lays out the three-layer architecture in detail. And when you are ready to evaluate platforms that handle context infrastructure out of the box, explore our comparison of analytics agent builder platforms.
The question is not whether analytics agents will work. It is whether your organization will be among the 5% that figures out the context problem, or the 95% that keeps rebuilding demos that never scale.
Frequently Asked Questions
Why do most AI data agents fail in production?
The short answer is missing context. Analytics agents break when they lack the institutional knowledge that experienced analysts carry: metric definitions, business rules, table lineage, and the tribal knowledge about which data sources are trustworthy. The model can generate valid SQL, but if it does not understand what "revenue" or "churn" means at your specific company, the answers will be confidently wrong.
What is the actual failure rate for AI analytics projects?
Research consistently shows that most AI pilots never reach production. Across multiple major studies from MIT, Gartner, and IDC, the numbers range from 50% to 95% of projects stalling or being abandoned before delivering measurable business value. The exact figure depends on how "failure" is defined, but the directional message is the same: the vast majority of analytics agent POCs do not survive contact with real users.
What is the difference between technical accuracy and semantic accuracy?
Technical accuracy asks whether the SQL is syntactically correct, queries the right tables, and applies the right joins. Semantic accuracy asks whether the answer actually means what the business thinks it means. Your agent might write perfect SQL that pulls from the wrong revenue table, or calculate churn using the wrong denominator. Most agents achieve decent technical accuracy but fail on semantic accuracy, which is where trust breaks down.
Can a semantic layer alone fix analytics agent accuracy?
A semantic layer is a strong start because it addresses metric definitions and business logic. But on its own, it covers only one of the three context layers agents need. You also need structural context (which tables exist and how they connect) and trust context (which answers have been validated by humans). Semantic layers also tend to degrade over time if not actively maintained, which can create a false sense of accuracy.
How did OpenAI solve this problem for their internal data agent?
OpenAI built multiple layers of context into their agent: table usage metadata, human annotations, code-level data definitions, institutional knowledge from internal documents, and a memory system that stores learned corrections. The key takeaway from their experience is that the model is only as good as the context it receives. Without rich, structured institutional knowledge, even frontier models produce unreliable analytics.
How long does it take to fix a failed analytics agent deployment?
It depends on the severity of your context gaps. If you already have a well-maintained semantic layer and solid schema documentation, addressing the Trust layer and tightening definitions may take a few weeks. If your context infrastructure is minimal, expect a longer runway. The fastest path is usually to start with the ten most-asked questions, ensure those are perfectly accurate, and expand incrementally from there.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







