
Data democratization needs more than dashboards. See how context layers and analytics agents turn access into trusted answers.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min

Every few years, someone declares that this is the year data finally belongs to everyone. New tools get bought. Dashboards get built. Access gets opened up. And then, quietly, the same thing happens that always does: the business users drift back to filing tickets, and the data team is right back to answering the questions it was answering before. Data democratization, the practice of making data usable by everyone in an organization rather than just analysts and engineers, has been promised for over a decade. For most of that decade it has under-delivered.
The strange part is that the tools mostly worked. Companies did get self-service software, and people did build dashboards with it. So why did the bottleneck never actually clear? The short answer is that access was never the hard part. Understanding was. A dashboard hands someone a number; it does not hand them the shared definitions and business logic that tell them whether the number means what they think it means. This guide is about that gap: why democratization kept stalling on it, what a strategy that finally closes it looks like, and why analytics agents are the first thing with a real shot at doing so.
Key Takeaways |
|---|
|
What Is Data Democratization?

Data democratization is the process of giving every authorized person in an organization the ability to find, understand, and act on data without depending on a specialist to retrieve or interpret it for them. In practice it combines three things: access to the data, tools that make the data usable, and the literacy or assistance required to draw correct conclusions. Remove any one of those and the effort stalls.
It is worth separating the goal from the mechanism. The goal is decision-making speed and autonomy: a store manager checking inventory trends, a marketer reallocating spend, a product lead reading feature adoption, all without a three-day wait. The mechanism has historically been self-service business intelligence, drag-and-drop dashboards, and governed semantic models. The recurring mistake is treating the mechanism as if it were the goal. Shipping a self-service tool is not the same as democratizing data, any more than handing someone a piano democratizes music.
The distinction that matters: Data democratization removes access barriers. Data literacy ensures people can interpret what they access. A recent literature review frames these as coevolving parts of a socio-technical system, not a single tool you can buy. Most failed initiatives bought the tool and skipped the system.
For analytics engineering leads, this framing is the whole game. You are usually the person who inherits the gap between "we gave everyone Tableau" and "nobody trusts the numbers." Understanding why that gap exists is the first step to closing it.
Why the Promise Kept Breaking

Data democratization has a long history of disappointing the people who championed it. The pattern is consistent enough that it reads like a script. Leadership decides to move to a self-service model. The data team rolls out a BI tool and some starter dashboards. Adoption spikes among the curious, then plateaus. Business users either get stuck and escalate anyway, or they push forward and reach the wrong conclusions. Six months later the data team is fielding the same volume of requests, the strategic roadmap is parked, and self-service is quietly declared a nice idea that did not work.
That is not a hypothetical. It is close to the consensus account among data leaders who have watched these projects up close. The reasons cluster into a few structural failures.
The Tools Were Too Complex for the People They Targeted
Self-service tools were built by data people, for data people, then handed to business users with different needs and different instincts. A drag-and-drop interface still assumes you know which table is authoritative, which join is correct, and which date field actually represents the transaction. Business users do not carry that knowledge. So the "self-service" tool became a tool that produced confident-looking but subtly wrong answers, which is arguably worse than no answer at all.
The result is what one practitioner account describes plainly: business users either get stuck and escalate to the data team for help, or they make mistakes and draw the wrong conclusions from the data. Either way, the promised efficiency gain evaporates.
Self-Service Was Too Fragile Without Governance
The flip side of accessibility is chaos. When everyone can build a dashboard, everyone does, and they all define "active user" or "monthly revenue" slightly differently. Gartner's analysis is blunt on this point: without adequate guardrails, self-service initiatives result in the duplication of dashboards, reports, and metrics that ultimately leads to data distrust. Once two executives show up to a meeting with two different revenue numbers, the entire program loses credibility, and credibility is the only currency democratization actually runs on.
Pro tip: If your self-service rollout has produced more dashboards than it has answered questions, that is the failure mode, not a transitional phase. Dashboard sprawl is the symptom of a missing semantic foundation, not a sign of healthy adoption.
The Maturity Gap Never Closed
Adoption numbers always looked encouraging, which masked the deeper problem. On Gartner's figures, roughly 74% of technology and software companies implemented some form of self-service analytics, but only 27% considered their implementation mature. That gap, between rolling something out and actually trusting it at scale, is where a decade of investment went to die. Tools shipped. Maturity did not follow.
The Promise, the Proliferation, and the New Problem
Here is the arc in one sentence. The promise was self-serve analytics. It delivered, in a narrow sense: dashboards proliferated, BI seats multiplied, and access genuinely expanded. But a new problem emerged underneath the success, and it is the problem that defines where we are now.
The Promise: Self-Serve Everything
The original vision was clean. Give business users intuitive tools, point them at the warehouse, and let them answer their own questions. Free the data team from the grind of ad-hoc requests so they could do strategic work. Surveys consistently show how much organizations want this: in one Google Cloud and Harvard Business Review study, 97% of leaders said organization-wide access to data and analytics is critical to their success. The appetite was never the issue.
The Proliferation: Dashboards Everywhere
The tools delivered on access. What they delivered was dashboards, lots of them. And a dashboard answers exactly one question: the one it was built to answer. The moment a user has a follow-up ("okay, but why did the Midwest dip?"), the dashboard is silent and the user is back in the queue. Self-service in the dashboard era meant self-service for anticipated questions only. Every unanticipated question, which is to say every interesting question, still routed through a human.
The New Problem: The Bottleneck Moved
This is the crucial shift. The bottleneck used to be data collection and access. That problem is largely solved. The bottleneck is now context: the warehouse holds the data, the tool can render it, but neither the tool nor the user holds the institutional knowledge required to turn a question into a trustworthy answer.
a16z makes this connection directly, and it is the throughline of this whole article. They observe that the recent wave of data agents failed for the same underlying reason self-service did: a lack of context. In their words, just like how the vision of fully self-serve analytics of years ago fell short, the vision for data agents seemed to fall short as well. Same disease, new decade. The tooling got dramatically better. The missing ingredient, context, stayed missing.
For a deeper treatment of why the self-service promise specifically broke down, our pillar on why the self-service analytics promise failed and how agents address it walks through the full history.
What Actually Closes the Gap

If the failures were structural, the fixes have to be structural too. A data democratization strategy that works is not a tool purchase; it is a combination of access, governed meaning, and a system that can do the interpreting for users who cannot do it themselves. Three things have to be true.
A Foundation of Governed Meaning
Before anyone self-serves anything, the organization needs a single, current definition of its core metrics and entities. This is the job a semantic layer is meant to do: encode what "revenue," "active customer," and "churn" actually mean so that every query and every tool resolves to the same answer. Without this Meaning layer, democratization just distributes disagreement.
The catch, and a16z is sharp on this, is that traditional semantic layers were hand-built by data teams in specialized syntax, wired to one BI tool, and prone to going stale the moment the person who maintained them left. The famous failure scenario: an agent asks for the revenue definition, finds a YAML file last updated by someone who departed a year ago, missing the two product lines launched since. The definition exists; it just is not true anymore.
Literacy or a Substitute for It
The reckoning of the self-service era is that you cannot train an entire company into data fluency. Data literacy programs help, and they remain a top-three challenge for nearly half of data and analytics leaders, but they do not scale to every employee fast enough to matter. The strategic question becomes: if you cannot make every user an analyst, can you give every user something that interprets data the way an analyst would? That question is what reframes the entire problem from "train the humans" to "encode the expertise."
Key insight: The most durable shift in democratization thinking is moving the burden of interpretation off the user and into the system. You stop asking every employee to learn what the data means, and start encoding what it means once, so the system can apply it for everyone.
Governance That Travels With the Data
Access without governance produced the dashboard sprawl described above. The fix is not to lock data back down; it is to make governance a property of the system rather than a manual gate. Metric definitions, access controls, and source-of-truth designations have to be encoded once and applied everywhere, automatically, so that broadening access does not multiply risk. This is the balance the research literature keeps returning to: democratization and governance are not opposites, they are requirements for each other.
Where Analytics Agents Fit In
This is where the story turns. For most of the past decade, the missing piece in data democratization was a way to give non-technical users the judgment of an analyst on demand. Dashboards could not do it. Search-based BI could not do it. The thing that can, at least in principle, is an analytics agent.
What an Analytics Agent Actually Does
An analytics agent is not a smarter dashboard. It receives a question in plain language, retrieves the relevant context (schema, metric definitions, business rules), generates the analysis, and validates the output before returning it. Where a dashboard answers one predefined question, an agent handles the follow-ups, the disambiguation, and the "why," which is exactly the work that used to force users back into the data team's queue.
This is what finally addresses the literacy barrier. The user does not need to know which table is authoritative or how revenue is defined, because the agent does. Democratization stops requiring that you turn every employee into an analyst, and starts requiring that you encode an analyst's knowledge once.
Why Agents Alone Are Not the Answer
Here is the trap, and it is the same trap self-service fell into. An agent without context is just a confident guesser. Connect a large language model to a warehouse with no encoded meaning and it will cheerfully produce wrong revenue numbers, because revenue is a business definition, not a column. This is precisely the wall the first wave of data agents hit. The lesson the market learned, as OpenAI documented after building its own internal data agent, is that high-quality answers depend on rich, accurate context. OpenAI's agent was grounded in multiple deliberate layers of context, not just a model pointed at a database.
So the agent is necessary but not sufficient. The sufficient part is the context underneath it.
The lesson the market already learned: An agent connected to a warehouse with no encoded meaning will confidently report the wrong revenue number, because revenue is a business definition, not a column. The first wave of data agents proved this at scale. The fix was never a bigger model; it was the context layer.
The Three Layers That Make Agents Reliable
The reliable version of an analytics agent rests on three layers of context, and most failed deployments solve one or two and skip the third.
Structure: What data exists, how tables relate, where the authoritative sources live, and how lineage flows. The agent has to know the map before it can read it.
Meaning: What the business terms mean here, specifically. Metric definitions, KPIs, business rules, and the tribal knowledge that usually lives in Slack threads and people's heads. This is the Meaning layer that a semantic model is meant to anchor, extended to cover the messy parts a YAML file never captured.
Trust: Which answers have been validated, which queries are golden, and what corrections users have already made. This is the layer that turns a plausible answer into a trustworthy one, and it is the layer almost no traditional tool provides.
This is the heart of why context engineering, not model selection, determines whether an analytics agent works in production. Encode all three layers and democratization finally has the foundation it always lacked. Encode one and you have rebuilt the self-service failure with a chat interface on top.
Data Democratization Tools: How the Categories Compare
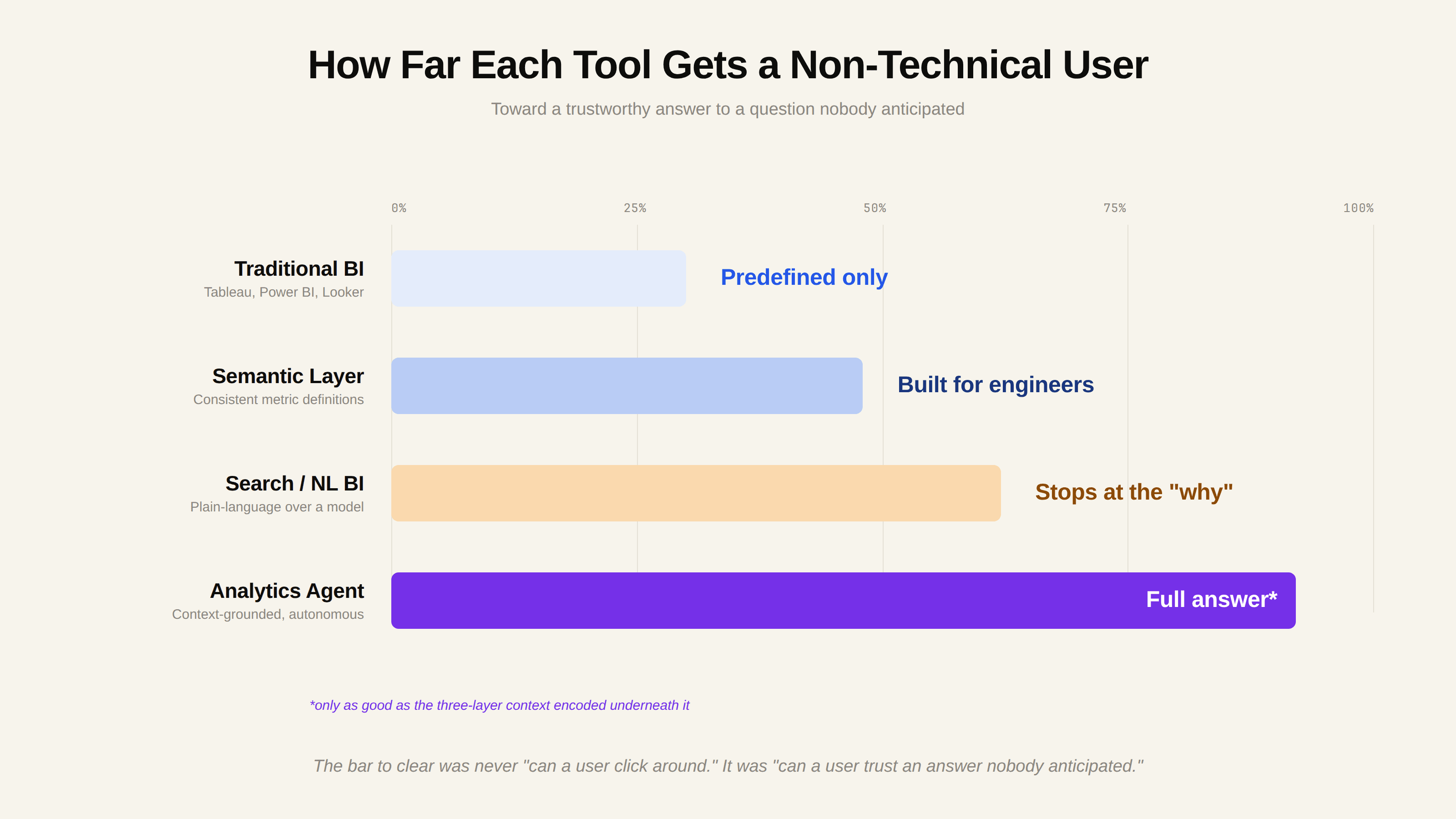
The data democratization tools market is crowded, and the categories blur together in vendor marketing. It helps to compare them by what job they actually do for a non-technical user, and where each one stops.
Tool Category | What It Democratizes | Where It Stops | Best For |
|---|---|---|---|
Traditional BI (Tableau, Power BI, Looker) | Access to predefined dashboards and visual exploration | Cannot answer unanticipated or follow-up questions | Teams with stable, well-understood reporting needs |
Semantic layer platforms | Consistent metric definitions across tools | Requires upfront modeling; serves engineers more than business users | Organizations standardizing the Meaning layer |
Search and NL-based BI | Plain-language questions over a defined model | Context limited to what is explicitly modeled; struggles with the "why" | Teams wanting lighter-weight querying |
Analytics agent platforms | Autonomous question-to-answer with context retrieval | Only as good as the context layer encoded underneath | Teams that need real self-service for non-technical users |
Traditional BI tools are not obsolete; they remain excellent at what they were built for, and most organizations will run them alongside whatever comes next. Semantic layer tools solve a real and necessary piece, the Meaning layer, but on their own they were designed for data engineers, not the business users democratization is supposed to serve. The newer agent platforms are the most promising for genuine self-service, but they are also the most likely to be deployed badly, because a slick agent over a thin context layer fails exactly where it matters most.
When you evaluate these categories, the question to keep asking is not "can a business user click around in it," but "can a business user get a trustworthy answer to a question nobody anticipated." That is the bar democratization was always trying to clear. For a structured way to assess the agent-platform category specifically, see our guide to what to look for in an analytics agent builder platform.
Where Democratization Efforts Go Wrong
The failures repeat because each wrong turn feels reasonable at the time. Three show up again and again.
1. Treating the Tool as the Strategy
Buying a self-service platform and considering the job done is the original sin. The tool is one component of a strategy that also includes governed meaning, encoded context, and a plan for the users who cannot interpret raw data. How to avoid it: start from the user's question and work backward to what the system needs to know to answer it, not from the tool's feature list.
2. Skipping the Meaning Layer
Democratizing access to data with inconsistent or undefined metrics guarantees the dashboard-sprawl outcome. How to avoid it: establish canonical definitions for your core metrics before broadening access, and treat keeping them current as ongoing work, not a one-time project. A definition that is right today and stale in eighteen months is the most common way agents and dashboards both fail.
3. Assuming Literacy Will Catch Up
Betting the whole strategy on training every employee into fluency has a poor track record. How to avoid it: invest in literacy where it pays off, but design the system so that a non-expert can get a correct answer without becoming an expert first. That is the entire point of putting an agent over an encoded context layer.
Bottom line: Every one of these mistakes is a version of the same error: solving the access problem and ignoring the comprehension problem. Democratization lives or dies on the second one.
How Agentic Analytics Delivers on the Original Promise
The reason this moment is different from the last decade is not that the tools got faster. It is that the architecture finally matches the problem. The original self-serve promise assumed users could interpret data if you just gave them access. They mostly could not, and no amount of dashboard polish fixed that. An analytics agent grounded in a real context layer inverts the assumption: it does the interpreting, so the user does not have to.
That is what makes agentic analytics the technology that finally makes democratization work at scale. Not because agents are magic, but because the combination of an agent plus encoded Structure, Meaning, and Trust is the first architecture that delivers trustworthy answers to unanticipated questions for non-technical users. The earlier eras delivered dashboards. This one can deliver answers.
The implication for analytics engineering leads is concrete. Your semantic layer is no longer just governance plumbing for BI tools; it becomes the Meaning layer that grounds an agent serving your entire company. The work you have already done on definitions and lineage is the foundation. The new work is encoding the rest of the context, the Trust layer especially, and choosing a system that uses all three.
If your team is weighing whether to assemble this yourself or adopt a platform purpose-built for it, the trade-offs are worth thinking through deliberately rather than by default. A platform that treats context infrastructure as the core product, rather than a feature bolted onto a notebook or a dashboard tool, is what lets a small team reach production-ready democratization without rebuilding the context layer from scratch for every use case.
Moving From Dashboards to Answers
The decade-long disappointment of data democratization was never really about the tools. It was about the gap between giving people access and giving people understanding. Dashboards closed the access gap and left the understanding gap wide open, which is why users kept landing back in the queue. Analytics agents, grounded in an encoded context layer, are the first approach that closes both, because they do the interpreting that the self-service era expected users to do for themselves.
If you are responsible for the semantic layer and the data quality that democratization depends on, the path forward is to treat your encoded context as the product, not the plumbing. To see how a context-first approach turns that foundation into trustworthy self-service for an entire organization, explore what to look for in an analytics agent platform.
Frequently Asked Questions
What is data democratization?
Data democratization is the process of making data accessible and understandable to everyone in an organization, not just analysts and engineers, so people can answer their own questions without depending on a specialist. It requires three things working together: access to the data, tools that make it usable, and either the literacy or the assistance needed to interpret it correctly. Access alone is not democratization; comprehension is the harder half.
Why do most data democratization efforts fail?
Most efforts fail because they solve access but ignore comprehension and governance. Self-service tools built for data teams get handed to business users who lack the context to use them correctly, producing wrong answers or escalations. At the same time, ungoverned self-service generates duplicate dashboards and conflicting metrics, which Gartner identifies as the leading cause of data distrust in self-service programs. The result is that only about a quarter of organizations reach a mature, trusted state.
What is the difference between data democratization and self-service analytics?
Data democratization is the goal: broad, autonomous access to trustworthy insights. Self-service analytics is one mechanism for pursuing that goal, historically through dashboards and drag-and-drop BI tools. The two are often conflated, which is part of why democratization stalled. Shipping self-service software is not the same as achieving democratization, because the software addressed access while leaving the comprehension and context problems unsolved.
What data democratization tools should I consider?
The main categories are traditional BI tools (Tableau, Power BI, Looker) for dashboard-based access, semantic layer platforms for consistent metric definitions, search and natural-language BI for lighter querying, and analytics agent platforms for autonomous question-to-answer workflows. Each democratizes a different slice and stops at a different point. The right choice depends on whether your users need predefined reporting or trustworthy answers to questions nobody anticipated, which is the harder and more valuable capability.
How do analytics agents help with data democratization?
Analytics agents remove the literacy barrier that blocked self-service. Instead of requiring a business user to know which table is authoritative or how a metric is defined, the agent retrieves that context, generates the analysis, and validates the result. This works only when the underlying context is encoded across three layers (Structure, Meaning, and Trust), which is why context engineering rather than model choice determines whether the approach succeeds in production.
Do I need a semantic layer for data democratization?
A governed source of metric definitions is essential, and a semantic layer is the standard way to provide it. That said, a semantic layer covers the Meaning layer only; reliable democratization at scale also needs Structure (what data exists and how it connects) and Trust (which answers are validated). A semantic layer is necessary but not sufficient on its own, which is why modern context layers are described as a superset of what traditional semantic layers covered.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







