
Stop answering the same data questions twice. See why ad-hoc queues keep growing and how context-aware analytics agents shrink them.

Ka Ling Wu
Co-Founder & CEO, Upsolve AI
10 min

Your data team is underwater, and most of what is pulling them down is work they have already done.
A request lands in Slack: "Can you pull churn for last week?" Two minutes, easy, so someone does it. Then thirty more arrive just like it, each a small variation on a question the team answered last month. By Friday the roadmap has not moved, your sharpest analyst is quietly eyeing the exit, and the backlog is somehow longer than it was on Monday. So you do the responsible-sounding thing and ask for another hire.
That instinct is the trap. To reduce your data team's ad-hoc request queue, you have to stop treating it as a volume problem and start treating it as a structural one. The same questions keep coming back, answers go stale before they land, and the context each answer depends on is stuck in people's heads instead of encoded somewhere a system can reach. Add analysts and you spread that load around; you do not change the math. The teams that shrink the queue for good encode the context once, let it handle the repeats, and free their analysts for the work that actually needs a human.
Key Takeaways |
|---|
|
Why the Ad-Hoc Request Queue Keeps Growing
Most data leaders feel the queue as a volume problem: too many requests, not enough hands. That framing is comforting because it implies a simple fix. It is also wrong, and the wrongness is exactly why the queue never shrinks. It grows for three structural reasons, and none of them yields to working faster.
The Same Questions, Wearing Different Costumes
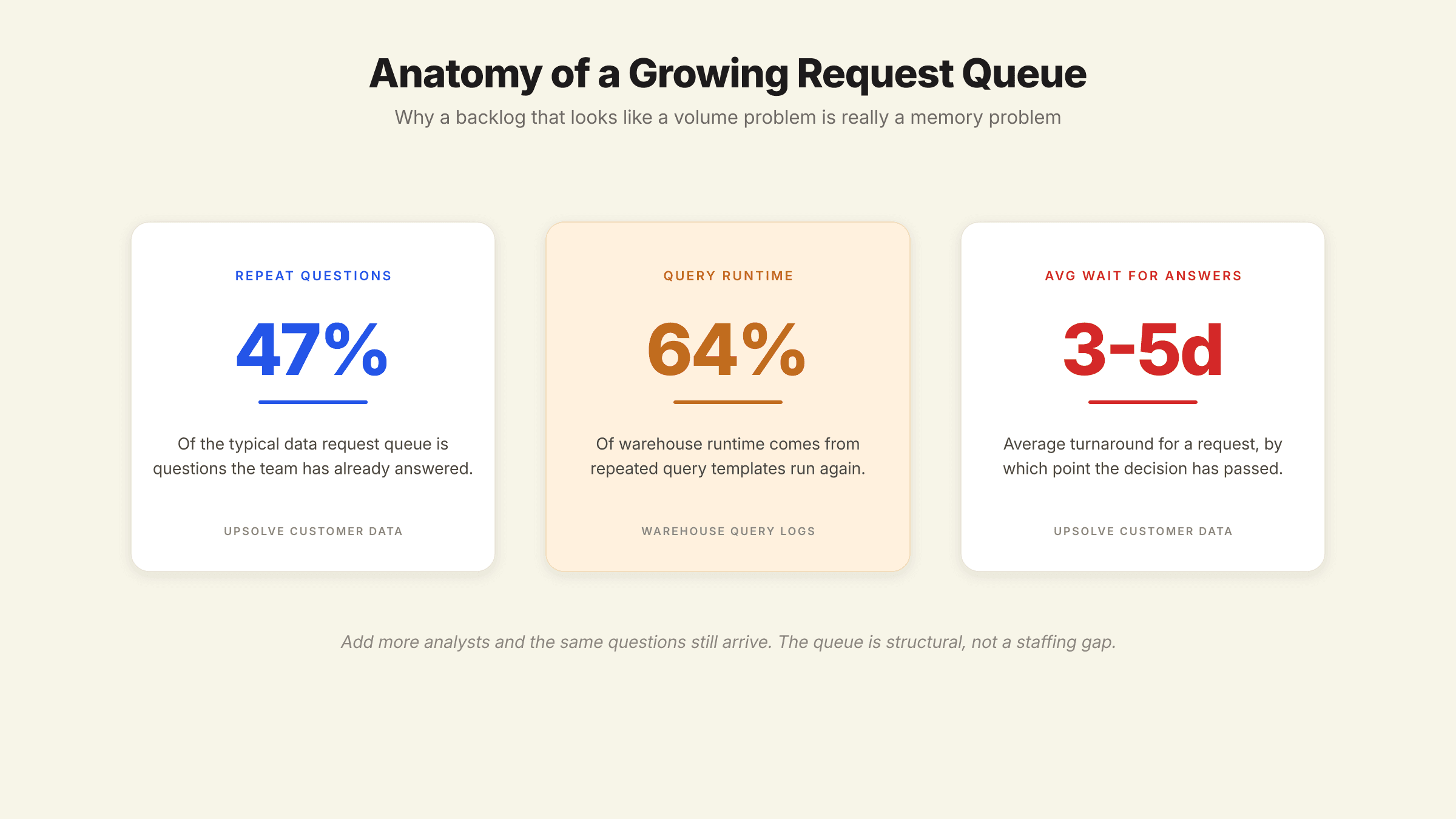
Look closely, and the flood of "quick pulls" is not a flood of new questions. It is a small set of recurring questions in different outfits. "What was churn last week," "how did churn look in Q1," and "break churn down by plan" are one underlying question with the parameters swapped.
The data backs this up. In that year-long study of a commercial warehouse, repeated parameterized query templates (the same query rerun with new values) accounted for roughly 64% of total cluster runtime, with the longest-lived templates executing tens of thousands of times. Upsolve's customer data lands in a similar place: about 47% of the typical queue is repeat questions. The analytics platform Fabi.ai goes further, estimating teams spend 70 to 80% of their time on repetitive requests rather than novel analysis.
If half or more of your queue is questions you have already answered, it is not a capacity problem. It is a memory problem. The organization keeps re-asking because the answers were never made reusable.
Answers That Go Stale Before They Land
The second driver is timing. Data has a short half-life. A request that takes days to fulfill (Upsolve's customer data points to an average wait of three to five days) often arrives after the decision it was meant to inform has already been made.
That sets off a vicious loop. Because answers are slow, stakeholders learn to ask early and ask often, padding requests to cover every angle "just in case." The padding inflates the queue, which slows answers further, which trains people to pad even more. The delay is not a side effect of the queue. It is one of the engines driving it.
The Context Locked in People's Heads
The third reason is the quiet one, and the most important. Every ad-hoc request carries hidden context that only an experienced analyst can supply: which table is authoritative, how "active user" is defined this quarter, which filter to apply, what last year's anomaly was really about.
When that context lives only in analysts' heads, in old Slack threads, and in a dbt YAML last touched in 2021, every request has to route through a human who holds it. The bottleneck is not the SQL; the SQL is trivial. The bottleneck is the institutional knowledge required to write the right SQL. That is why the queue is, at root, a context problem rather than a workload one.
Why Hiring More Analysts Doesn't Scale
When the queue grows, the instinct is to grow the team. It feels responsible. It is also the trap.
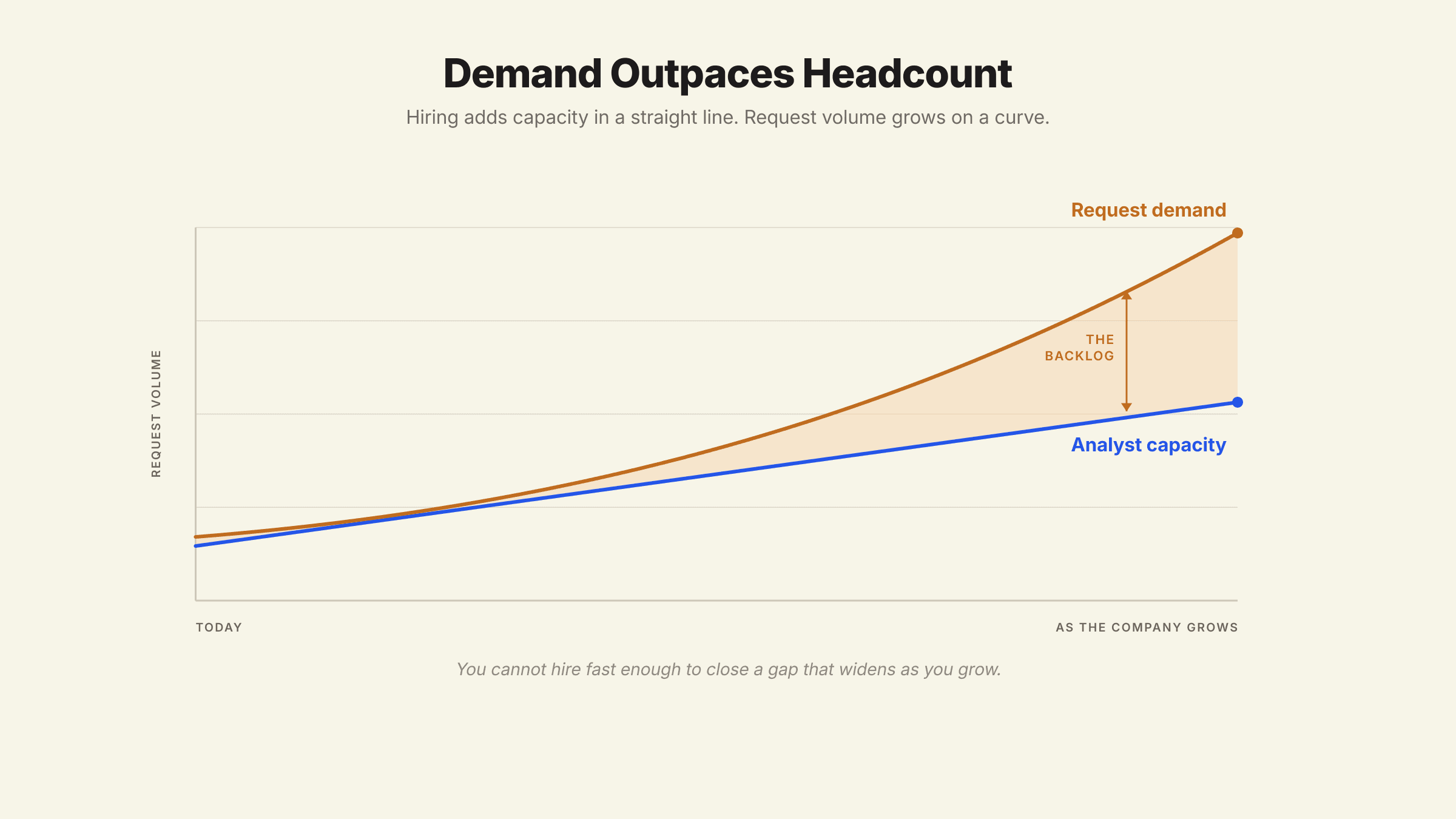
The Math Works Against You
Hiring adds linear capacity to a problem that grows non-linearly. As a company scales, stakeholders, products, metrics, and data sources all multiply, and each one multiplies the questions that can be asked. Demand outruns any realistic hiring plan. The U.S. Bureau of Labor Statistics projects data-related roles to grow about 34% by 2034, far above the average occupation, precisely because organizations keep trying to hire their way out of a structural gap.
There is a supply ceiling too. The World Economic Forum's 2025 Future of Jobs report ranks big data specialists among the fastest-growing roles in the world. You are competing for scarce talent to fill a hole that deepens as you fill it.
Adding People to a Broken Process Multiplies the Chaos
Even setting cost and scarcity aside, throwing people at the queue can make things worse. As The Seattle Data Guy puts it, when a large share of a team's work is already getting sidelined by interruptions and quick requests, adding new people heightens the problem. New hires need onboarding, they need the same institutional context the veterans hold, and in the meantime they add coordination overhead. You have bought cost and friction without removing the cause.
The Burnout Tax
There is a human cost as well. Analysts did not train in statistics and data modeling to spend their days copy-pasting canned queries, and the constant context-switching between firefighting and deep work erodes both quality and morale. Repetitive request loads are a well-documented driver of burnout and attrition. When your best analyst leaves, the institutional context in their head walks out the door with them, and the queue gets worse.
The Problem Is Structural, Not a Headcount Problem
Step back and the pattern is clear. The queue is large because the same questions recur, slow because answers go stale, and human-bound because the context needed to answer lives in people. Each of these is structural. None is fixed by more hands.
Naming the problem correctly points straight at the solution. If the queue is mostly repeat questions, the fix is to make answers reusable. If the bottleneck is missing context, the fix is to encode that context somewhere a system can reach it. The structural framing is what unlocks the structural fix.
It is also why the standard tactical playbook, which we will cover next, helps at the margins but never solves the problem. Intake forms, prioritization, and documentation all manage symptoms. They do not change the fact that a human still has to be in the loop for every answer.
The Tactical Fixes (and Why They Plateau)
Before the structural fix, give the tactical playbook its due. These moves are real, and you should make them. They simply have a ceiling.
Triage and Intake
Routing requests through a structured intake (a form, a ticket queue, a "what decision will this inform?" question) filters out low-value asks and stops Slack drive-bys from jumping the line. Genuinely useful. It reduces noise. But it does not reduce the underlying number of legitimate repeat questions; it just orders them.
Prioritization Frameworks
Scoring requests by business impact versus effort helps you spend scarce analyst time where it matters. Useful again. But prioritization is rationing. It decides which questions wait, not whether they have to be asked of a human at all.
Canned Queries and a Data Catalog
Building a library of reusable query snippets and a data dictionary of common metrics, as Metabase's team recommends, is the closest tactical move to a real fix, because it starts to make context reusable. The limit is that a canned query still needs a human to find it, parameterize it, run it, and interpret it. It speeds up the repeat work; it does not remove the human from the loop.
Self-Service BI Dashboards
The classic answer has been self-service: build dashboards, let stakeholders answer their own questions. It was the right instinct, and it delivered, sort of. Dashboards proliferated. But a new problem emerged: a dashboard only answers the questions you anticipated when you built it. The moment a stakeholder needs a follow-up it does not cover, they are back in your queue. Self-service shifted the queue; it did not erase it.
Bottom line: Every tactical fix manages the queue. None dissolves the structural cause, which is that a human must supply context for every answer. To actually shrink the queue, you have to break that constraint.
How Analytics Agents Address the Root Cause
This is where the conversation has shifted over the last two years. An analytics agent is software that takes a question in plain language, retrieves the relevant context, runs the analysis, validates the output, and returns a trustworthy answer on its own. Unlike a dashboard, it can handle the follow-up. Unlike a copilot that assists an analyst, it acts autonomously.
If most of your queue is repeat questions, an agent that answers them reliably absorbs the bulk of the queue at the source. The business user gets an answer in seconds instead of waiting days, and analysts get their week back for work that genuinely needs judgment. Even the warehouse vendors frame it this way now: Databricks describes agentic analytics as a way to handle routine insight requests automatically and shrink the reporting backlog.
That is the promise. It comes with a serious catch.
Why Most Agents Fail at This
An agent without context fails the way an underprepared new hire fails. It does not know that "revenue" means ARR here and run-rate there. It does not know which of your six "users" tables is authoritative. It does not know that Q1 had a backfill that distorts the comparison. So it returns an answer that looks confident and is wrong, and trust collapses on the first bad number.
This is not hypothetical. MIT NANDA's State of AI in Business 2025 found that roughly 95% of enterprise GenAI pilots deliver no measurable impact, and traced the failure not to model quality but to a "learning gap": tools that do not adapt to a company's workflows, data, and context. The venture firm a16z reaches the same conclusion, arguing that data agents are essentially useless without the right context. When OpenAI built its own internal data agent, it found that high-quality answers depended on rich, accurate context layered into the system.
The Three Layers an Agent Needs
So the real question is not "should we use an agent?" It is "what does an agent need to answer the queue reliably?" The answer is a structured context layer with three parts:
Structure: what data exists and how it connects. Schemas, tables, lineage, relationships, and usage patterns, so the agent knows where to look.
Meaning: what the data means at your company. Metric definitions, KPIs, business rules, and the tribal knowledge that decides whether "active user" is a 7-day or 30-day window.
Trust: which answers have been validated. Verified queries, golden assets, corrections, and usage signals, so the agent reuses known-good answers instead of plausible-looking guesses.

Most tools solve one layer and call it finished. A semantic layer covers Meaning. A warehouse covers Structure. Almost nothing covers Trust. An agent needs all three, which is why the discipline of curating and encoding that context, context engineering, is the real work behind a queue that finally shrinks. The agent is the delivery mechanism. The context is what makes it trustworthy.
A Practical Path to Shrinking the Queue
Putting it together, here is a sequence that moves from triage to durable reduction. Think of it as climbing from symptom management to root-cause fix.
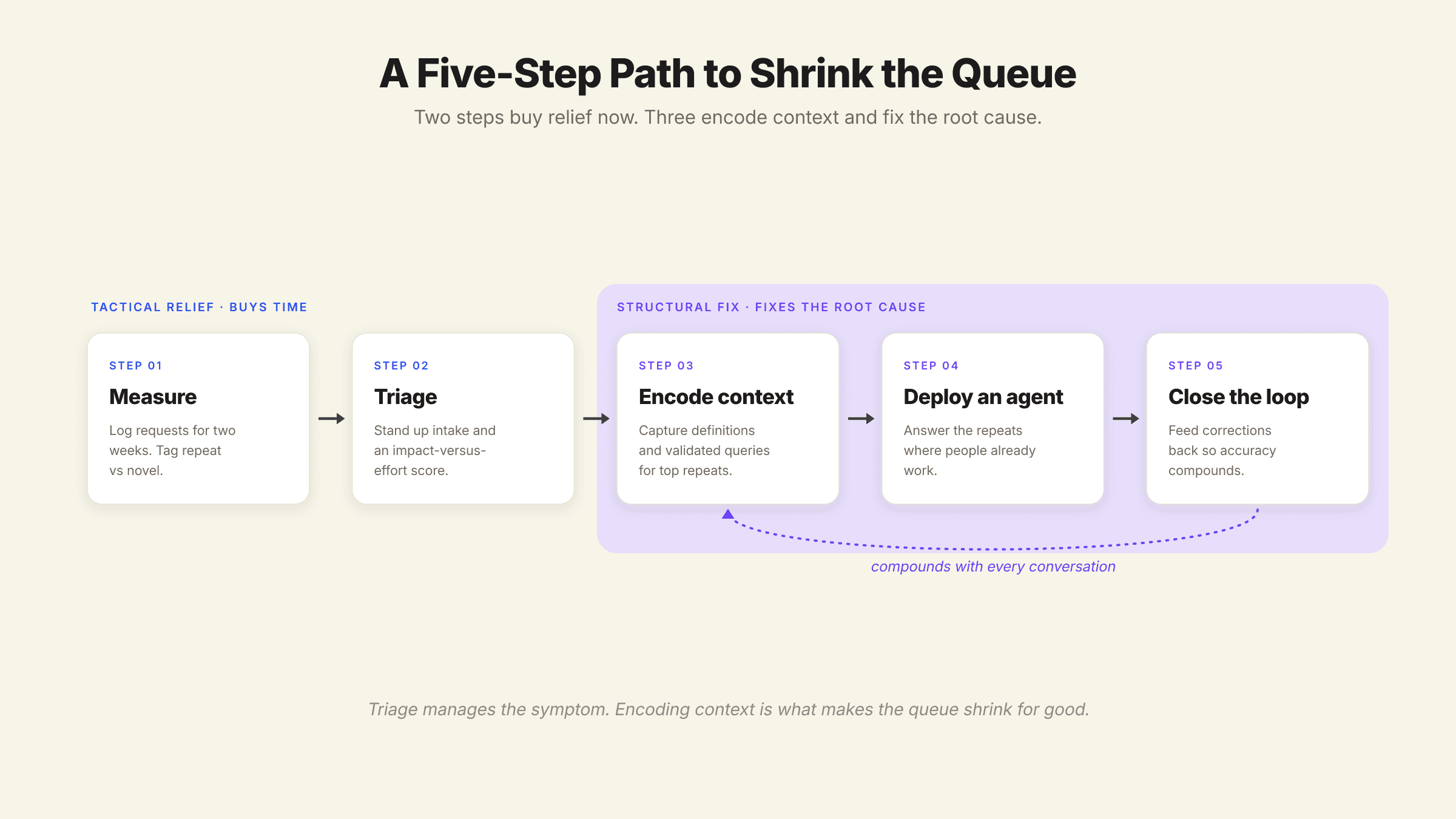
Measure the queue first. For two weeks, log every request, who asked, and how long it took, and tag each as repeat or novel. Most teams are stunned by how concentrated the queue is on a few recurring questions. This is your baseline and your business case.
Apply triage and prioritization immediately. Stand up an intake form and a simple impact-versus-effort score. This buys breathing room while you build the structural fix. Necessary, not sufficient.
Encode your top repeat questions as context, not just answers. For the recurring 20% of questions that drive most of the load, write down the metric definitions, the authoritative tables, and the validated query for each. You are building the Meaning and Trust layers whether or not you adopt an agent.
Deploy an agent against the encoded context. With context in place, an analytics agent can field the repeats directly, where your stakeholders already work (Slack, Teams, your product). Route only the genuinely novel questions to humans.
Close the loop. Every real conversation exposes a context gap: a term the agent misread, a definition that was missing. Feed those corrections back so accuracy compounds over time. This is what separates a production-ready system from a demo.
Pro tip: Do not start by buying a tool. Start by measuring your queue and encoding your top ten repeat questions. That work makes any downstream solution dramatically more effective, and it is the part most teams skip.
Three Traps That Keep the Queue Full
1. Treating It as a Volume Problem
The most common error is reading the growing queue as "we need more analysts." Hire without fixing the structural cause and you add cost and onboarding overhead while the queue keeps climbing. Diagnose before you staff.
2. Buying an Agent Before You Encode Context
The mirror-image error is assuming an AI tool will fix the queue out of the box. An agent without a context layer produces confident wrong answers and burns stakeholder trust on the first bad number. Context first, agent second.
3. Polishing the Symptom Instead of the Cause
Endlessly refining your intake form and prioritization matrix feels productive, but it is symptom management. These tools order the queue; they do not shrink it. Spend a fixed budget of effort on triage, then redirect the rest toward making answers reusable.
Choosing a Platform That Shrinks the Queue
If you decide an agent is the right structural fix, the evaluation question becomes which platform actually delivers all three context layers rather than just one. That is the difference between a feature bolted onto a BI tool and purpose-built context infrastructure. General-purpose agent builders give you orchestration but no analytics context. Warehouse-native tools give you Structure but lock you to one source. The teams that succeed look for platforms built for the full encode-deploy-tune loop. To weigh your options against the criteria that matter (context management, reliability, embedding, and security), see our guide to evaluating analytics agent builder platforms.
Stop Answering the Same Questions Twice
Reducing your ad-hoc request queue starts with a reframe: it is a structural problem rooted in missing context, not a workload you can hire your way out of. Measure the queue, encode the context behind your most common questions, and let a context-aware system field the repeats so your analysts can focus on work that needs a human. Do that, and the same ten questions stop landing in your inbox every week.
None of this requires a bigger team, just a different target. Fix the structure once, and the queue stops refilling itself with questions you have already answered.
Frequently Asked Questions
Why does my data team's ad-hoc request queue keep growing?
Mostly because a large share of requests are repeat questions asked in slightly different forms, because slow turnaround pushes stakeholders to over-ask, and because the context needed to answer lives in analysts' heads. Industry query-log research has measured repeated templates at around 64% of warehouse runtime, and Upsolve's customer data puts repeats near 47% of the queue. It is a structural problem, not simply a volume one.
Will hiring more analysts reduce the ad-hoc request queue?
Usually not for long. Hiring adds linear capacity to demand that grows non-linearly, and when most of a team's time is already lost to interruptions, adding people tends to heighten the problem rather than fix it. Headcount also competes for scarce talent and carries onboarding and burnout costs. Fix the structural cause first, and hire for genuinely novel work.
How much of a typical data queue is repeat questions?
Estimates vary by organization, but the share is high. Upsolve customer data puts it near 47%, query-log research has measured repeated templates at roughly 64% of cluster runtime, and analytics teams commonly report spending 70 to 80% of their time on repetitive requests. The takeaway is the same: most of your queue is questions you have already answered.
Can AI or analytics agents reduce ad-hoc requests?
Yes, but only with the right context. An analytics agent can answer recurring questions autonomously and absorb the bulk of the queue, freeing analysts for complex work. Without an encoded context layer, agents produce confident wrong answers, a major reason most enterprise GenAI pilots reach no measurable impact. Encode context first.
What is the difference between self-service BI and an analytics agent for reducing the queue?
Self-service BI hands stakeholders dashboards that answer the questions you anticipated when you built them. The moment a follow-up falls outside the dashboard, the request returns to your queue. An analytics agent handles open-ended and follow-up questions in natural language, covering the long tail a fixed dashboard cannot. Dashboards shift the queue; agents with context can shrink it.
How long does it take to meaningfully reduce the queue?
Triage and prioritization deliver relief within days. The structural fix takes longer because it means encoding your top repeat questions as reusable context, but it is measured in weeks, not quarters, especially if you start with the recurring 20% of questions that drive most of the load. The key is sequencing: quick triage now, structural encoding next.

Try Upsolve for Embedded Dashboards & AI Insights
Embed dashboards and AI insights directly into your product, with no heavy engineering required.
Fast setup
Built for SaaS products
30‑day free trial







